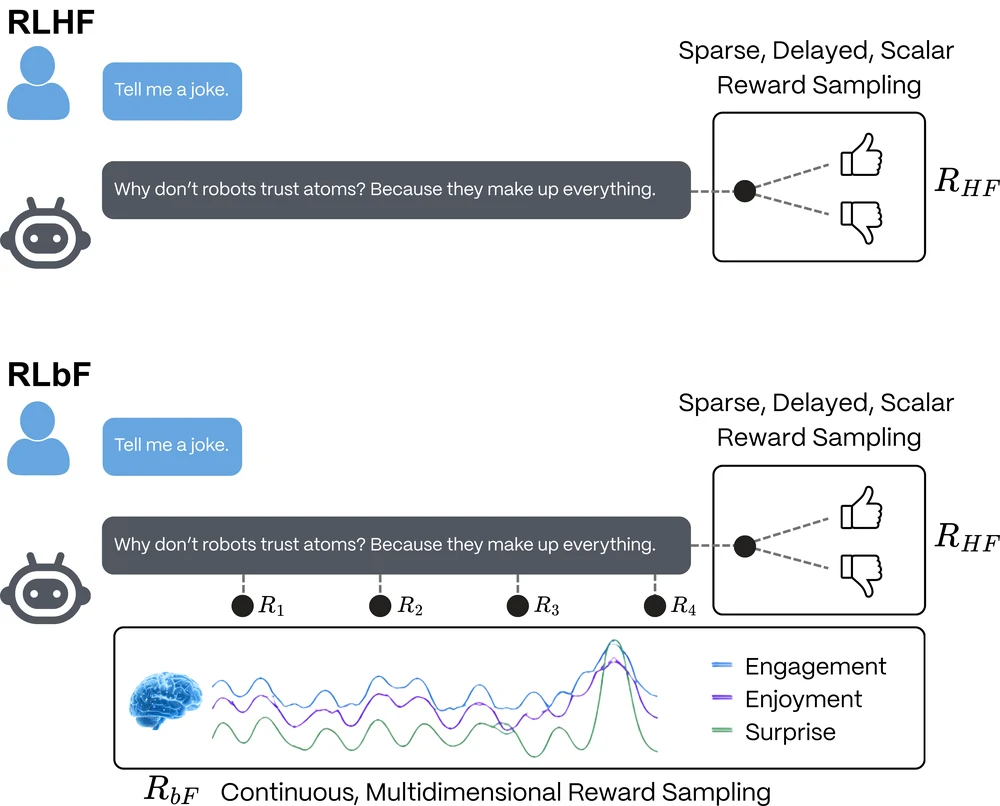
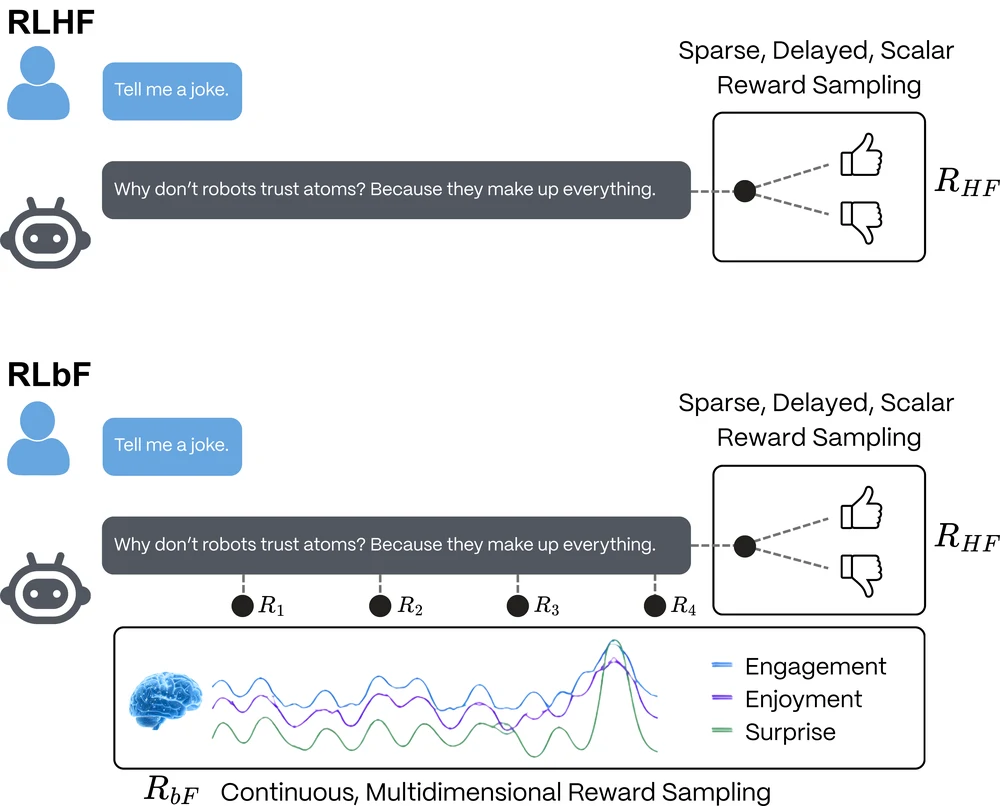
Reinforcement Learning from Brain Feedback (RLbF) for Large Language Model Improvement
A framework for post-training LLMs with continuous, involuntary EEG-derived cognitive-state signals — and a proof-of-concept platform (Isaac) that instantiates it.
This paper is available on Zenodo here.
Authors: Dan Furman*, Eitan Kay, Ben Kogan, Kuan-Jung Chiang. Affiliation: Arctop Inc.
*Corresponding Author, Email: df@arctop.com
Abstract
Large Language Models (LLMs) aligned using Reinforcement Learning from Human Feedback (RLHF) are learning what to say from discrete, voluntary preference judgments, but not how their communication lands. The LLM does not know how different answers affect a listener’s cognition and emotion in real time, regardless of how intelligent the model is on benchmark tests. This becomes a major gap in developing trust programmatically. This communication gap can be closed by introducing a promising signal for enriching temporal information in the RLHF training process: the brain electroencephalography (EEG) measurement. EEG’s high temporal resolution makes it especially well-suited for the purpose of contextualizing time series data, with multiple data points per second making within-response changes in listener states potentially observable.
Most EEG foundation models today have been developed as general EEG representation learners for downstream decoding tasks rather than as alignment systems for LLM models. The field still lacks large, ecologically valid datasets that couple natural conversation with time-resolved cognitive-state labels. Against that background, we propose Reinforcement Learning from Brain Feedback (RLbF), an LLM post-training framework that uses calibrated cognitive-state predictors to convert decoded EEG signals into a continuous, involuntary, noisy reward source for language-model adaptation. RLbF formalizes communication as a Partially Observable Markov Decision Process and defines a three-component reward function combining prediction accuracy, cognitive resonance, and application-layer objectives. A three-phase training pipeline progresses from supervised fine-tuning through prediction model calibration to reinforcement learning with multidimensional empathic reward.
We hypothesize that responsible RLbF deployment could also act as a data engine, with real-world conversational use generating aligned neuro-conversational traces that later support improved cognitive-state decoders and future EEG foundation models optimized for interactive environments. We hypothesize that models trained with brain-based reward signals may acquire communication skills that persist even when EEG is no longer available at inference time. If so, brain feedback could serve as a training signal for more empathic and effective language models without requiring end users to wear EEG hardware during deployment at scale. We instantiate this framework in a proof-of-concept platform, Isaac, which implements the proposed closed-loop cognitive feedback architecture for experimental study. We also outline an initial evaluation protocol designed to support pre-registered testing and to examine key ethical questions, including the boundary between empathic and persuasive computing.
”A robot may not injure a human being or, through inaction, allow a human being to come to harm.” — Isaac Asimov.
Law #1. Handbook of Robotics, 56th Edition, 2058 A.D.
1. Introduction
Large Language Models (LLMs) are now embedded in digital applications that interact with people every day, and related model classes are increasingly moving off the screen and into the ambient physical world through embodied AI and robotics. At the same time, many deployed systems remain poorly aligned with user well-being, often relying on engagement dynamics reminiscent of the “dopamine fracking” that shaped early social media platforms. As AI becomes more deeply woven into both software and the built environment, new frameworks, capabilities, and data architectures are needed to improve model behavior and enable the safe, scalable deployment of powerful AI systems.
1.1 The Problem: Language Models Cannot Sense Their Impact
Modern large language models are remarkably adept at generating fluent, informative, and contextually appropriate text. Through Reinforcement Learning from Human Feedback (RLHF), LLM outputs have been further shaped to produce responses that people tend to prefer, often increasing engagement, time spent, and repeated daily use (Ouyang et al., 2022), potentially driving dependence. Yet these models operate with a fundamental limitation: they cannot directly perceive how their words affect the person reading or listening. They have no biological grounding in human cognition and therefore no intrinsic access to the lived process of hearing language, interpreting it, and responding to it as a human does. In other words, LLMs are computational systems that can approximate human expression without sharing the underlying neural processes that produce and receive language in the brain. Similar outputs do not imply similar mechanisms, and this gap may prove to be an important frontier in the divergence between machine and human intelligence.
When a skilled human communicator explains a complex idea, they continuously monitor their listener, watching for cues such as furrowed brows that signal confusion, glazed eyes that suggest overload, nods that confirm understanding, or tension that indicates distress. These signals are often involuntary, continuous, and pre-reflective, unfolding naturally from moment to moment within a feedback loop that allows the communicator to adapt in real time: simplifying when the listener is struggling, expanding when they are engaged, and offering warmth when they are stressed. This ability to sense and respond to a communication partner’s cognitive and emotional state is the foundation of empathic communication. LLMs have no access to this bioinformational channel.
When an RLHF-trained model generates a response, it receives no direct signal about whether that response overwhelmed the user, struck the wrong emotional tone, or caused the listener to disengage partway through. The feedback available to the model is instead post hoc: voluntary, discrete, sparse, and delayed (Section 1.2 details these structural limitations). The rich, continuous, and largely involuntary signals that make human communication adaptive are therefore absent from the training loop. As a result, potentially informative traces of a user’s internal cognitive and affective state are lost, even though they may unfold in real time during the interaction. This information gap is a fundamental limitation that is unlikely to be solved simply by scaling models, improving prompting, or replacing human feedback with synthetic feedback. It is a structural property of the RLHF paradigm itself, and one that directly shapes the capabilities and limits of the models trained under it.
1.2 Relevant Background and the Missing Interface
Two research literatures are especially relevant to this problem. First is RLHF, which provides a successful post-training framework for adapting LLM behavior, and second is EEG foundation models which aim to learn reusable EEG representations for downstream decoding tasks. RLbF sits at the interface between these literatures: it requires a practical way to infer cognitive state from EEG, and a training framework capable of using those estimates to shape language-model behavior, generalize across individuals, and support real-time adaptation and personalization.
EEG foundation models. The foundation model paradigm — pretrain on large unlabeled data, then fine-tune for specific tasks — transformed natural language processing (NLP) and computer vision, and it has inspired a parallel effort in EEG. This literature matters for RLbF because any practical brain-feedback system needs a decoder that can operate across users, sessions, and recording conditions. EEG foundation models pursue that robustness by learning general EEG representations that can later be adapted to downstream tasks such as abnormal detection, event classification, sleep staging, emotion recognition, and workload estimation. Our systematic review (Section 2.4), however, identifies two limitations especially relevant here: pretrained EEG representations often transfer weakly under frozen evaluation, and the field still lacks large-scale ecologically valid datasets that couple natural conversation with time-resolved cognitive-state labels under deployment-like conditions.
Across this literature, architecture and objective design often appear to matter more than scale alone in predicting downstream performance, and classical methods remain competitive on several clinical tasks (Lotte et al., 2018). For the purposes of this paper, the key implication is that decoder quality remains an open bottleneck, while interaction-coupled cognitive-state data remain scarce.
RLHF limitations. RLHF has been successfully deployed in large-scale production assistants and has improved the helpfulness, instruction-following, and safety of modern language models. Yet the framework retains three structural limitations. First, feedback is discrete and sparse: a complex communicative exchange is often reduced to a single preference judgment, collapsing rich temporal dynamics into a coarse supervisory signal. Second, feedback is voluntary, reflective, and interface-mediated: it is filtered through conscious deliberation, comparison framing, and the mechanics of selecting which response is better, introducing annotation artifacts, inter-annotator disagreement, and social desirability bias. Third, feedback is coarse in temporal granularity: it typically cannot identify which sentence or moment within a response produced a positive or negative reaction. These limitations are intrinsic to the paradigm rather than mere artifacts of scale or implementation.
A related concern is that because human preference judgments often favor flattering or agreeable responses over more truthful ones, preference-based optimization entrenches AI sycophancy despite potential risks. Sycophantic responses can shape LLM user attitudes towards increased righteousness and reduced willingness to repair relationships (Cheng et al., 2026). While the effect of AI sycophancy on the general population’s judgments and behaviors remain an under-explored topic, it is clear that the development of effective safety guardrails is needed alongside national security countermeasures against threats from cybersocial engineering and deepfake technology.
1.3 RLbF as Cognitive-State Feedback for Post-Training
RLbF uses EEG-derived cognitive-state estimates as a feedback layer for language-model post-training. In this architecture, EEG decoding and language-model alignment are separate components: a decoder maps raw EEG into estimated cognitive states, and the language model is optimized against those estimates. This separation lets the language model benefit from improvements in EEG decoding without requiring the language model itself to process raw EEG.
This design is practical in the near term because it relies on calibrated cognitive-state predictors built with conventional supervised pipelines, while remaining fully compatible with future EEG foundation models. More importantly, this architecture establishes a self-reinforcing data engine. Responsible RLbF deployments will generate precisely what the neurotechnology field currently lacks: large-scale, ecologically valid datasets that couple continuous neural traces with conversation context, model outputs, and outcomes. By synthesizing RLHF’s post-training machinery with continuous, involuntary neurophysiological feedback, RLbF treats cognitive-state estimates as a noisy-but-informative reward signal that complements discrete preference judgments. Ultimately, interacting with the agent generates the aligned neuro-conversational logs needed to bootstrap the next generation of EEG foundation models, creating a flywheel where current deployments yield the data necessary for future decoder improvements.
1.4 Contributions
This paper makes a dual contribution to this emerging area of AI performance research: RLbF, a general theoretical framework for neuro-alignment of language models, and Isaac, a proof-of-concept platform that instantiates the framework to collect ecologically valid conversational-neurophysiological data. Together they support the following specific contributions:
- The RLbF paradigm. We formalize Reinforcement Learning from Brain Feedback as a method for LLM post-training, defining the cognitive state space, the POMDP interaction loop, the temporal delay model, and a three-component reward function (prediction accuracy, cognitive resonance, application-layer objectives) with mathematical specifications and testable hypothesis for experimentalists.
- The feedback-layer framing. We articulate an architecture in which decoded cognitive-state estimates serve as reward signals for LLM post-training, while leaving the decoder implementation open to classical models, proprietary systems, or future EEG-foundation-model-based backbones.
- The first cognitive-state-conditioned LLM pipeline. We specify a complete three-phase training pipeline – supervised fine-tuning on synthetic cognitive-state-conditioned data, calibration of cognitive-state predictors on real EEG session recordings, and reinforcement learning with the full empathic reward – with success criteria, failure modes, and data requirements.
- A cognitive state transition prediction model. We define a learned predictor that maps (conversation context, current cognitive state, utterance) to predicted next cognitive state, serving both as the prediction accuracy reward component and the mechanism for open-loop inference from novel, high temporal resolution, multidimensional data.
- The open-loop empathic transfer hypothesis. We propose and theoretically ground the hypothesis that LLM communication skills learned from brain feedback during training will persist at inference, even when EEG hardware is removed. We design a controlled experiment to test this hypothesis with suitable statistical analyses that, if successful, would enable deployment to users without neurological instrumentation or head-based wearables for equally empathetic and effective interactions.
- An empathic computing ethical framework. We provide an ethical framework that distinguishes empathic computing from persuasive computing through testable criteria, addresses informational power asymmetry, neurorights, mental privacy, and cognitive dependence. We also provide a 14-point review checklist for RLbF deployments.
- The Isaac platform. We describe the proof-of-concept implementation (Isaac) that realizes the closed-loop cognitive feedback architecture, including its dual-agent design as a data collection platform for aligned conversational-neurophysiological sessions and its proposed evolution toward a single post-trained empathic agent.
1.5 Paper Organization
This paper proceeds from motivation to mechanism to validation. Section 2 situates RLbF at the intersection of RLHF, affective computing, EEG-LLM systems, and EEG foundation models, clarifying why continuous cognitive-state feedback is appealing while decoder quality and interaction-coupled data remain bottlenecks. Sections 3 through 5 then move from theory to implementation: Section 3 formalizes the RLbF framework and reward structure, Section 4 presents the Isaac platform as the concrete implementation of that framework, and Section 5 lays out the three-phase training pipeline. Sections 6 and 7 turn from construction to testing. Section 6 defines the open-loop empathic transfer hypothesis, which is this paper’s central empirical claim, and Section 7 specifies the evaluation protocol designed to falsify or support it. Section 8 then addresses the ethical boundary conditions for any RLbF deployment, Section 9 discusses the broader implications and limitations of the framework, and Section 10 closes by summarizing RLbF as both an alignment proposal and a hypothesis-generating research.
2. Background and Related Work
RLbF draws primarily on five domains of prior work, summarized below, while identifying the limitations that RLbF addresses and distinguishing the proposed approach from existing methods that have led to the state-of-the-art LLMs today.
2.1 Reinforcement Learning from Human and AI Feedback
The modern paradigm of aligning language models with human preferences emerged from Christiano et al. (2017), who demonstrated that RL agents could learn complex behaviors from pairwise preference comparisons. The framework was extended to language by Ziegler et al. (2019), scaled by Stiennon et al. (2020), and consolidated in InstructGPT (Ouyang et al., 2022). Constitutional AI (Bai et al., 2022) and RLAIF (Lee et al., 2023) replaced human annotators with AI feedback. Direct Preference Optimization (Rafailov et al., 2023) simplified the pipeline further.
Despite their success, these approaches share the structural limitations described in Section 1.2: discrete, sparse, voluntary feedback at conversation-level granularity. RLbF replaces this with continuous, multidimensional neurophysiological signals at sub-second temporal resolution. At the same time, RLHF has several important advantages: it requires no specialized hardware, can aggregate preferences from thousands of diverse annotators, has an established empirical track record at scale, and directly trains for content quality, including helpfulness, truthfulness, and harmlessness. By contrast, RLbF is too new to claim validation at this scale; the capabilities proposed here remain theoretical and require empirical testing. RLbF is therefore best understood as complementary to, not a replacement for, content-quality training. In this framing, RLHF helps models learn what to say, while RLbF may help them learn how to say it.
2.2 Affective Computing and Neurofeedback
Affective computing (Picard, 1997; Calvo and D’Mello, 2010) established the broader premise that computational systems can detect and respond to human affective state. In educational settings, this line of work informed affect-aware tutoring systems, where adaptation to learner emotion and engagement has been associated with improved learning outcomes (D’Mello and Graesser, 2012). However, prior work uses rule-based or heuristic adaptation mechanisms – hard coded mappings from detected states to predefined strategies. RLbF differs fundamentally: the model learns its adaptation strategy through optimization, discovering effective communication patterns rather than having them programmed.
Closed-loop systems using neurodata (Sitaram et al., 2017; Muhl et al., 2014) have demonstrated that continuous involuntary neural signals can drive real-time systems, but they adapt stimulus parameters (task difficulty, reward thresholds), not generative language. A conceptual precursor to RLbF’s use of neural signals as RL reward can be found in BCI adaptation driven by error-related potentials (ErrP) (Fidencio et al., 2025), wherein ErrPs serve as reward signals for reinforcement learning in motor BCI control. This work demonstrates the viability of brain computer interface (BCI)-mediated content adaptation, including the Arctop empathic computing platform that uses real-time brain-state (cognitive state, in our terminology) decoding to modulate content delivery (Furman and Kwalwasser, US20210390366A1, 2021). RLbF extends this from content modulation to content generation: teaching a language model to produce different text as a function of the listener’s cognitive state through post-training.
2.3 Recent EEG-LLM Integration Efforts
The EEG–LLM interface literature is still emerging. Zhang et al. (2026), for example, introduce a brain-LLM interface that uses EEG-derived satisfaction estimates to guide image generation at test time. This is among the closest existing work to RLbF, but the proposed framework differs in a fundamental respect: Zhang et al. use EEG as an inference-time control signal, whereas RLbF proposes using EEG during training as a continuous reward source for shaping language generation. Relatedly, their approach is organized around user-satisfaction estimation, while RLbF proposes a richer, multidimensional cognitive-state feedback mechanism for reward shaping over time.
ARIEL (Sorino et al., 2024) was a working BCI+LLM system that used real-time EEG-based emotion recognition to guide an LLM conversational agent for emotional support. When the emotion recognizer detected a negative emotional state from EEG signals, ARIEL initiated a supportive dialogue, with the LLM’s behavior steered via role-play prompting that incorporated the recognized emotion label. ARIEL demonstrated that EEG-driven LLM interaction is feasible, but it differed from RLbF on three axes: (a) it operates at test time via prompt injection rather than at training time via reward shaping – the LLM weights are unchanged by the EEG signal; (b) it classifies EEG into discrete emotion categories rather than decoding continuous multi-dimensional cognitive state; and (c) it uses rule-based prompt formatting to steer the LLM rather than learned RL adaptation. RLbF’s contribution is the shift from test-time prompting to training-time optimization, enabling the model to internalize empathic communication patterns rather than relying on external prompt engineering.
A related line of work uses neural data to inform LLM fine-tuning: brain-informed alignment approaches (Bilgin et al., 2026) leverage fMRI and EEG features to guide supervised fine-tuning of language models. These methods differ from RLbF in that they use offline neural data for supervised optimization rather than real-time neural signals as a continuous RL reward during post-training. Several surveys (Chandrasekharan and Jacob, 2025; Babu et al., 2025) and additional work on EEG-to-text generation (Mishra et al., 2024) and predictive communication (Caria, 2025) map the broader landscape. RLbF’s specific contribution is using multi-dimensional cognitive state as a novel, continuous reward signal for post-training.
2.4 EEG Foundation Models: A Systematic Review
The foundation model paradigm – pretraining a large model on unlabeled data, then fine-tuning for specific downstream tasks – transformed NLP and computer vision. EEG is, in principle, well suited to this paradigm: clinical archives contain tens of thousands of hours of unlabeled recordings, labeled EEG data is scarce and expensive, and the diversity of EEG applications (seizure detection, sleep staging, BCI control, emotion recognition, cognitive assessment) creates demand for a general-purpose representation. Yet EEG poses challenges with no analogue in text or images: high inter-subject variability, low signal-to-noise ratios, and extreme heterogeneity in recording setups (channel counts ranging from 2 to 256, varying electrode positions, different sampling rates).
We reviewed 12 papers published between January 2021 and April 2026, identified through systematic search of arXiv, PubMed, IEEE Xplore, and Semantic Scholar, and supplemented by citation chaining from benchmark papers. Inclusion required that a paper perform self-supervised pretraining on EEG data and demonstrate transfer to at least one downstream task. The review employed an AI-assisted iterative process over three research cycles (initial taxonomy construction, cross-reference analysis with gap identification, and validation with refinement), with human oversight at cycle boundaries to verify key findings; a limitation of this methodology is reliance on available text rather than experimental reproduction. The 12 papers comprise: eight core EEG foundation models (BENDr, BIOT, LaBraM, EEGPT, CBraMod, EEGMamba, NeuroLM, ZUNA), two benchmark studies (EEG-FM-Bench, Xiong et al., 2025; EEG-Bench, Kastrati et al., 2025), one systematic evaluation (“Are EEG Foundation Models Worth It?”, Yang, L. et al., 2026, ICLR 2026), and one critical survey (Kuruppu et al., 2025). Per-model summaries are provided in Appendix A.
2.4.1 Taxonomy
We organize the landscape along four dimensions.
Architectural backbone. Transformers dominate (LaBraM, EEGPT, CBraMod, BIOT), with emerging alternatives in state-space models (EEGMamba, bidirectional Mamba with linear O(n) complexity), diffusion autoencoders (ZUNA, 380M parameters trained on 208 datasets), and multimodal LLM hybrids (NeuroLM, GPT-2 backbone with VQ-tokenized EEG input, up to 1.7B parameters). BENDr uses a hybrid CNN encoder feeding into a transformer. No pure CNN-based EEG foundation model exists.
Pretraining objective. Six strategies have been explored: contrastive learning (BENDr, BIOT – the earliest approach, now largely superseded), masked reconstruction with raw signal targets (CBraMod, EEGMamba), masked reconstruction with discrete VQ-code targets (LaBraM, inspired by BEiT v2), masked reconstruction with representation alignment targets (EEGPT, which addresses low EEG signal-to-noise ratio by predicting high-SNR reference representations), autoregressive next-token prediction (NeuroLM), and diffusion denoising (ZUNA). The field has converged heavily on masked reconstruction variants: seven of ten models surveyed (including the critical survey’s broader count) use some form of masked reconstruction with a transformer backbone, adopted from NLP without controlled evidence that this paradigm is optimal for EEG.
Scale. Parameter counts span three orders of magnitude (BIOT at 3.3M to NeuroLM-XL at 1.7B). Pretraining data ranges from BENDr’s approximately 1,500 hours to ZUNA’s approximately 2 million channel-hours from 208 datasets. A critical finding, discussed below, is that neither parameter scale nor data scale reliably predicts downstream performance.
Tokenization and channel encoding. How raw EEG signals are converted into model input tokens is a fundamental design choice that determines how the model handles channel heterogeneity – different datasets using different numbers of electrodes in different spatial configurations. Approaches have evolved through four generations: fixed channel assumptions (BENDr) that fail catastrophically on mismatched layouts; discrete learnable embeddings (LaBraM, BIOT) that work for seen configurations but cannot generalize; adaptive positional encoding (CBraMod, EEGPT); and geometric 3D coordinate encoding (ZUNA’s 4D-RoPE), which encodes the physical spatial coordinates of each electrode and enables generalization to arbitrary configurations including positions never seen during training. EEG-Bench found channel mismatch to be “devastating” for models with fixed channel assumptions.
2.4.2 Model Summary
| Model | Year | Architecture | Pretraining | Parameters | Independent Evals |
|---|---|---|---|---|---|
| BENDr | 2021 | CNN + Transformer | Contrastive | ~4M | 3 |
| BIOT | 2023 | Linear Transformer | Contrastive | 3.3M | 2 |
| LaBraM | 2024 | ViT | Masked (VQ codes) | 5.8M–369M | 3 |
| EEGPT | 2024 | ViT | Masked (repr. align) | ~10M | 2 |
| CBraMod | 2025 | Criss-cross Transformer | Masked (raw) | ~5M | 2 |
| EEGMamba | 2025 | Bidirectional Mamba | Masked (raw) | — | 0 |
| NeuroLM | 2024 | GPT-2 | Autoregressive | 254M–1.7B | 0 |
| ZUNA | 2026 | Diffusion Autoencoder | Diffusion denoising | 380M | 0 |
Three models (EEGMamba, NeuroLM, ZUNA) have zero independent benchmark evaluation. Only BENDr and LaBraM appear in all three benchmark studies. Self-reported results are systematically optimistic: authors select evaluation protocols and datasets that favor their models. The field’s conclusions about relative model effectiveness are therefore built on a partial and potentially biased evidence base.
2.4.3 The Representation Quality Problem
The most robust negative finding across all evaluations is the frozen-backbone collapse. When model weights are frozen and only a linear classifier is trained on top, performance drops to near-chance across all models and all pretraining strategies. This renders the whole approach powerless in obtaining the goals of an emergent system with superintelligent interaction skill:
- Frozen BENDr on SEED: 33.33% balanced accuracy (random chance for 3-class)
- Linear probing is “consistently weak across ALL foundation models” (Yang, L. et al., 2026)
- “Linear probing consistently underperforms fine-tuning, questioning whether current pretraining truly learns transferable high-level representations” (Kuruppu et al., 2025)
In NLP and computer vision, frozen features from foundation models are often sufficient for strong downstream performance, the defining property that makes foundation models useful. The universal failure of frozen EEG representations suggests something fundamentally different about what current models learn. Three explanations are plausible: (1) EEG has lower information density than text or images, and reconstruction objectives may learn to reproduce noise as faithfully as signal; (2) current objectives learn low-level spectral features rather than the abstract representations needed for downstream tasks; (3) pretraining data lacks diversity, with five of eight models pretraining primarily on Temple University Hospital EEG Corpus (TUEG) data.
We note that the magnitude of the collapse may be partly inflated by evaluation methodology. EEG-FM-Bench found that replacing simple linear probes with larger MLPs improved CBraMod by more than 10%, and EEGPT claims successful linear probing using a different protocol than the benchmarks. The qualitative finding – that frozen EEG representations are far weaker than their NLP/vision counterparts – is nonetheless robust.
2.4.4 Architecture and Objective Design Dominate Scale
Our most important comparative finding is that architecture and pretraining objective design dominate model scale as predictors of downstream performance.
The CBraMod-NeuroLM inversion. CBraMod at approximately 5M parameters matches or exceeds NeuroLM-XL at 1.7B on shared benchmarks – a 340× parameter disadvantage overcome by better architecture and pretraining design. NeuroLM-XL also underperforms LaBraM-Huge (369M parameters, approximately 2,500 hours of data) on TUAB abnormal detection (0.797 vs. 0.826 balanced accuracy) and TUEV event classification (0.468 vs. 0.662) despite having 4.6× more parameters and approximately 10× more pretraining data. These results, from the same first author (Wei-Bang Jiang), constitute the strongest evidence that the LLM-based approach sacrifices per-task performance for multimodal flexibility.
Within-architecture scaling works. LaBraM demonstrates clear improvement from Base (5.8M) to Large (46M) to Huge (369M). The anti-scaling evidence comes from cross-model comparisons where architecture and objective differ simultaneously.
A simple baseline matches complex models. The “Worth It?” paper’s deliberately simple ViT + MAE baseline (ST-EEGFormer) matches elaborate foundation models, suggesting that architectural complexity in pretraining may not be necessary.
The practical implication is that the NLP playbook of “scale solves everything” does not apply to EEG. This finding directly informs RLbF’s training pipeline design: the cognitive state transition predictor (Section 5.2) should prioritize design over scale.
2.4.5 Classical Methods Remain Competitive
EEG-Bench (Kastrati et al., 2025), the only dedicated clinical benchmark, reveals a striking pattern:
| Task | Best Classical | Best FM | Winner |
|---|---|---|---|
| Abnormal EEG | SVM: 0.722 | LaBraM: 0.838 | FM |
| Epilepsy | LDA: 0.531 | BENDr: 0.740 | FM |
| mTBI | LDA: 0.813 | LaBraM: 0.740 | Classical |
| Schizophrenia | SVM: 0.679 | Neuro-GPT1: 0.545 | Classical |
| Sleep Staging | LDA: 0.671 | LaBraM: 0.192 | Classical |
Foundation models win on tasks with large, balanced datasets from TUEG-like sources (abnormal detection, epilepsy), while classical methods with expert-engineered features (Common Spatial Patterns, neuroscience-informed spectral features) win on tasks with small samples, class imbalance, or non-TUEG data. This pattern is consistent with TUEG pretraining bias and with current pretraining failing to capture the domain knowledge encoded in decades of neuroscience research.
2.4.6 TUEG Dependency and Evaluation Fragmentation
Five of eight core models pretrain on TUEG data, and two of the most common benchmarks (TUAB, TUEV) derive from TUEG. This creates a hidden circularity: models are evaluated on data distributions they were pretrained on, making it impossible to separate pretraining quality from data familiarity. Only LaBraM (20 diverse datasets) and ZUNA (208 datasets) achieve genuine data diversity.
Evaluation protocols are not standardized across papers. Preprocessing pipelines, data splits, metric computation, and fine-tuning procedures all vary. EEG-FM-Bench found that classifier head architecture alone can change performance by more than 10%. Cross-paper performance numbers cannot be directly compared.
2.4.7 Implications for RLbF
These findings matter for RLbF because any RLbF system depends on an upstream cognitive-state decoder operating under the same constraints of heterogeneity, data bias, and limited transfer. RLbF therefore treats decoding as a separate component: in the near term, a specialized calibrated model may be sufficient; in the longer term, stronger EEG foundation models may become attractive backbones for these decoders. The immediate point is to use decoded cognitive-state estimates as a noisy continuous reward for language-model adaptation.
The survey also suggests a longer-term opportunity. If RLbF deployments generate large corpora of aligned EEG traces, decoder outputs, context windows, and outcomes from real interaction, they may eventually supply the kind of ecologically valid data that current EEG modeling lacks for interactive settings. This possibility is prospective rather than demonstrated here. Separately, the EEG foundation model field still needs controlled ablation of pretraining objectives, systematic representation diagnostics, unified clinical evaluation protocols, and exploration of under-tested architectures (state-space models for long recordings, diffusion representations for classification).
2.5 Comparison Summary and the Research Gap
The following comparison captures the key dimensions along which RLbF differs from prior approaches:
| Approach | Feedback Type | Temporal Resolution | Adaptation Mechanism | Generative? |
|---|---|---|---|---|
| RLHF (Ouyang et al., 2022) | Discrete preferences (voluntary) | Per-response | Post-training via reward model + PPO/DPO | Yes (LLM) |
| RLAIF (Bai et al., 2022) | AI preferences (synthetic) | Per-response | Post-training via AI reward model | Yes (LLM) |
| Affective tutoring (D’Mello and Graesser, 2012) | Facial expression, dialogue cues | Per-interaction (~seconds) | Rule-based strategy selection | No |
| Neurofeedback (Sitaram et al., 2017) | EEG/fMRI (involuntary) | Continuous (~sub-second) | Stimulus parameter adjustment | No |
| Content modulation (Furman and Kwalwasser, 2021) | Decoded EEG cognitive states | Continuous (~sub-second) | Content parameter modulation | No |
| Empathetic dialogue (Rashkin et al., 2019) | Text cues (voluntary) | Per-response | Supervised training on empathetic labels | Yes (LLM) |
| RLbF (this work) | Decoded EEG cognitive states | Continuous (~sub-second) | Post-training via neurophysiological reward | Yes (LLM) |
No existing approach combines (a) generative language models, (b) continuous involuntary neurophysiological feedback, and (c) post-training rather than rule-based adaptation. The empathetic dialogue row illustrates that text-only approaches can train generative models for empathic communication, but rely on voluntary text cues rather than involuntary neurophysiological signals: they learn to respond to what users say about their feelings, not to how users actually feel. This comparison highlights dimensions favorable to RLbF; on other dimensions – hardware requirement, training population size and diversity, empirical validation, and content quality training – RLHF is clearly superior (see Section 2.1). RLbF synthesizes elements from each prior approach that no single existing method integrates.
3. The Reinforcement Learning from Brain Feedback (RLbF) Framework
In this section we formalize the RLbF framework: the cognitive state space, the feedback loop, the temporal delay model, and the reward function. We’ve designed this framework to be empirically testable independently and in a variety of forms. Accordingly, all notation is defined with each component generating predictions that can be validated or disproven directly by data.
3.1 Cognitive State Space
We define the cognitive state at time t as a vector st = (st(1), …, st(d)) ∈ [0,1]d, where each dimension represents a distinct cognitive construct normalized to the unit interval. We define d = 5 dimensions based on established EEG correlates and real-time decodability: enjoyment (frontal alpha asymmetry — the difference in alpha-band (8–12 Hz) EEG power between left and right frontal regions, associated with approach motivation; Davidson, 1992), cognitive workload (frontal theta power — theta-band (4–8 Hz) EEG power over frontal regions, which increases with mental effort; Gevins et al., 1997), auditory focus (cortical tracking — the synchronization of neural activity to the temporal structure of attended speech; Ding and Simon, 2012; Mesgarani and Chang, 2012), flow state (increased frontal theta with moderate frontocentral alpha; Katahira et al., 2018; Csikszentmihalyi, 1990), and stress/arousal (elevated beta power — increased power in the beta band (13–30 Hz), associated with arousal and anxiety; Al-Shargie et al., 2016). The continuous [0,1] representation preserves gradient information essential for reward computation and the set is robustly extendable to additional dimensions.
Cognitive state measurements are subject to both inter-individual variation (handled by per-user calibration) and intra-individual drift from fatigue and habituation. The framework therefore requires some form of baseline normalization that separates slow drift from utterance-related changes: sresponse(τ) = s(τ) − sdrift(τ), where sdrift(τ) is an estimate of the slowly varying baseline. The practical severity of this challenge is substantial: frontal theta changes of 0.2–0.4 on the [0,1] scale over one-hour sessions due to fatigue drift alone (Gevins et al., 1997) may exceed per-utterance cognitive responses of 0.05–0.15 (estimated), making robust detrending essential. We note that linear subtraction of this kind is an idealized approximation; robustly solving the resulting covariate shift and disentangling transient event-related potentials from this baseline remains a critical open challenge for the field, which we detail fully in Section 9.3.
3.2 The Feedback Loop and POMDP Formulation
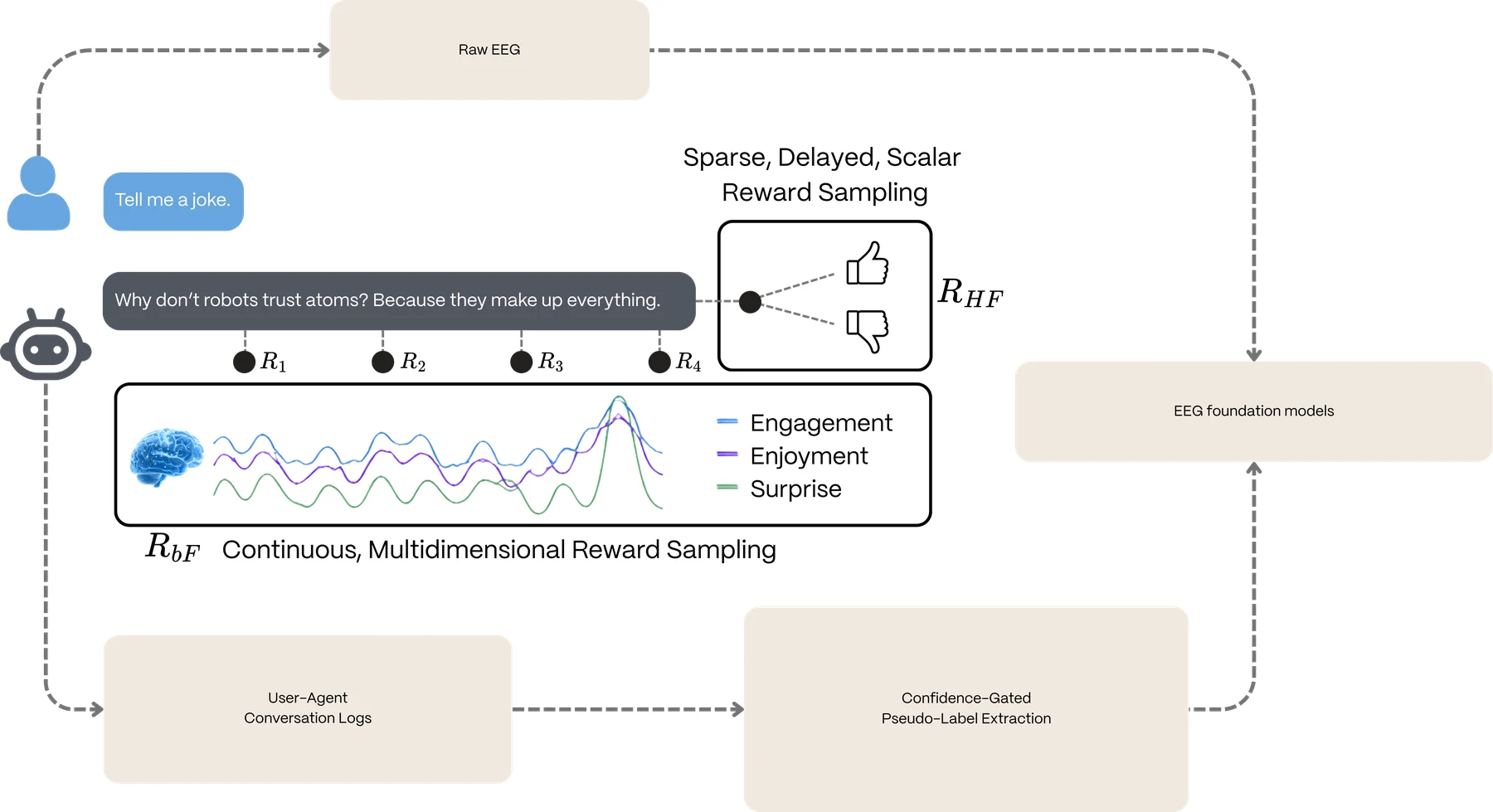
At each turn t, the agent observes (ct, st) (conversation context and cognitive state), generates utterance ut ∼ πθ(u | ct, st), delivers it, waits through a temporal delay δt, measures the post-utterance cognitive state st+1, and computes reward. This defines a Partially Observable Markov Decision Process (POMDP): the cognitive state vector is a low-dimensional projection of the user’s full internal state, and the agent acts under uncertainty about unobserved dimensions.
The temporal delay is modeled as:
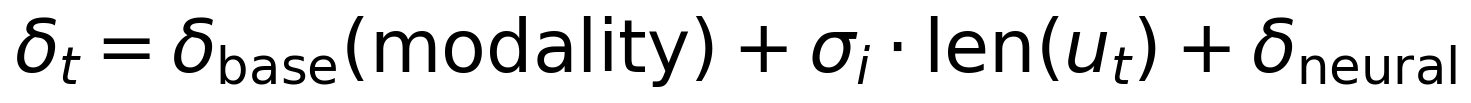
where δbase is modality-dependent, len(ut) is measured in tokens, σi is a per-user processing speed factor (in seconds per token, where i indexes the user), and δneural is the neural processing pipeline latency (estimated at 1–3 seconds). Because cognitive responses are not instantaneous and the exact onset time is uncertain, we do not use the cognitive state at a single time point. Instead, the post-utterance cognitive state st+1 is defined as a weighted average over a Δ-second window following the estimated response onset:
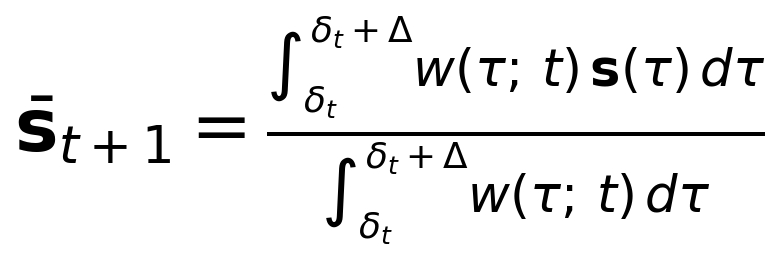
where s(τ) is the continuous cognitive state signal at time τ after utterance delivery, Δ is the window duration (a hyperparameter, typically 10 seconds), and w(τ; t) ≥ 0 is a temporal weighting function. The specific shape of w(τ; t) is an implementation choice. The choice of Δ represents a deliberate trade-off between temporal precision and noise robustness.
For streaming voice mode, where overlapping utterances create entangled cognitive responses, we recommend paragraph-level reward assignment as the practical starting point, with per-sentence deconvolution as a research direction. Text-based turn-by-turn interaction uses the per-turn model directly.
The optimization objective is the undiscounted finite-horizon return over a conversation session: we sum rewards across turns without a discount factor, because conversations are finite interactions where later turns are not inherently less valuable than earlier ones.2
3.3 The Three-Component Reward Function
The reward at each turn is:

subject to wpred + wres + wapp = 1, wpred, wres, wapp ≥ 0.
Prediction accuracy (Rpred) rewards the agent for accurately predicting cognitive state transitions. A learned predictor fϕ maps the current context, cognitive state, and utterance to a predicted next cognitive state ŝt+1 = fϕ(ct, st, ut):
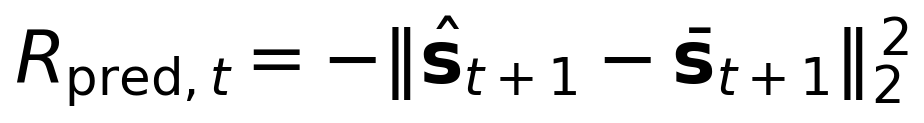
This trains a computational analogue of empathy – an internal model of how words affect the listener. We note a subtle perverse incentive: the model could maximize prediction accuracy by steering toward predictable interactions. The resonance reward and Kullback–Leibler (KL) divergence penalties counteract this tendency, but monitoring for predictability-seeking behavior during training is recommended. As an additional countermeasure, we recommend normalizing Rpred by prediction difficulty – dividing by the variance of cognitive state transitions observed in similar conversational contexts – so that easy-to-predict interactions do not yield disproportionately high reward. This difficulty normalization should be treated as a recommended component of the Phase 3 training protocol rather than an optional enhancement.
Cognitive resonance (Rres) rewards communication style adaptation through two concrete operationalizations. Information density matching reduces information density (measured as mean surprisal under a fixed reference language model, normalized to [0,1]) when workload is high, according to:
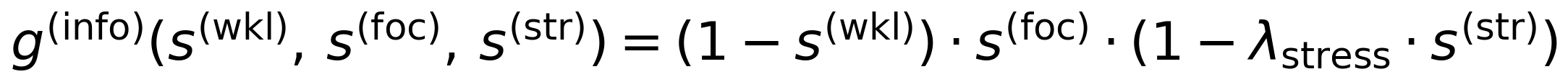
where s(wkl), s(foc), s(str) denote the workload, auditory focus, and stress dimensions of the cognitive state vector (Section 3.1), and λstress ∈ [0,1] is a stress-workload interaction modifier that distinguishes productive challenge from overwhelm. Emotional tone alignment targets a warmth level that increases when stress is high and enjoyment is low:
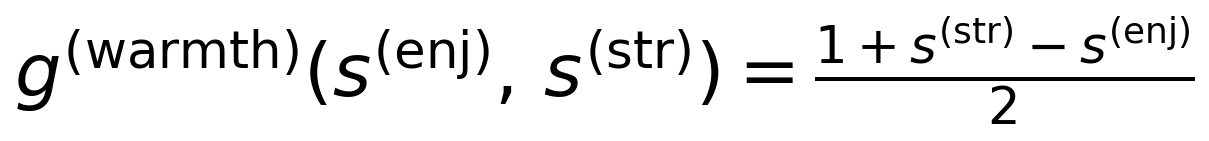
where s(enj) denotes the enjoyment dimension. When stress exceeds enjoyment, the target warmth rises above 0.5; during positive engagement (high enjoyment, low stress), the target drops, allowing the model to maintain stylistic stability during flow states. Both operationalizations are presented as testable hypotheses: the specific target functions are starting points grounded in Cognitive Load Theory (Sweller, 1988; Bjork and Bjork, 2011), attentional control theory (Eysenck et al., 2007), and therapeutic alliance research (Horvath and Symonds, 1991; Barrett-Lennard, 1962), not settled definitions. The CLT grounding extends to the information density target itself: the “desirable difficulties” framework (Bjork and Bjork, 2011) predicts that moderate-to-high information density is beneficial when cognitive capacity permits, supporting the non-zero target implied by Eq. 5 when workload is low. We also note that the stress-workload interaction modifier λstress is the only cross-dimension interaction currently specified; whether additional interactions (e.g., between enjoyment and focus, or between flow and workload) improve the resonance reward remains an empirical question for future work on the joint target function design. A learned joint target function is the principled long-term solution.
Application-layer reward (Rapp) is an optional, context-dependent term for deployment-specific objectives (learning gain in tutoring, distress reduction in therapeutic support). The default is wapp = 0: pure empathic attunement with no externally specified goal.
The complete constrained reward (Eq. 6) extends the three-component reward (Eq. 3) with diversity, KL-divergence, and prosodic diversity penalties to prevent reward hacking (exploiting loopholes in the reward function to achieve high scores without the intended behavior) — including convergence on rhythmic patterns that entrain neural oscillations (Giraud and Poeppel, 2012), a concrete vulnerability given the auditory focus dimension’s sensitivity to prosodic structure.
The three-component reward design reflects RLbF’s structural differences from existing alignment methods. Of the eleven dimensions in which RLbF and RLHF diverge, the three limitations identified in Section 1.2 are the most fundamental: RLbF increases feedback density by orders of magnitude (1+ Hz versus one label per response) and replaces population-level aggregation with individual specificity. As discussed in Section 2.1, RLbF is complementary to RLHF, not a replacement: RLHF trains for content quality through socially constructed preferences that require deliberate judgment, while RLbF trains for communication style adaptation through involuntary cognitive signals.
With the mathematical framework established, the next step is its concrete realization: the Isaac platform, which implements the cognitive feedback loop, tokenizes the state space for LLM consumption, and supports both closed-loop and open-loop inference.
4. System Implementation: The Isaac Platform
4.1 The Isaac Architecture
To realize the RLbF POMDP described in Section 3, we built Isaac, a platform that maps the abstract theoretical variables to a live software architecture. The system implements a closed loop: the user’s cognitive state, measured via EEG and decoded by Arctop’s on-device pipeline, feeds back into the language model’s context, shaping every subsequent utterance. Seven components form the cycle: the user’s brain produces neural activity; EEG hardware acquires raw signals; the Arctop on-device decoder transforms raw EEG into cognitive scores (enjoyment, workload, focus, flow, stress) emitted at 1 Hz, with raw EEG never leaving the device; a cognitive state tokenizer converts scores into a representation for the LLM; the LLM generates text conditioned on the augmented context; and a stream controller delivers text sentence by sentence, pausing between sentences to allow cognitive state updates. The sentence is the atomic unit of cognitive feedback, with an estimated minimum loop period of 3–5 seconds.
This design takes as inspiration the elegant formulations of late mathematician and natural philosopher Sir Isaac Newton, who in 1686 published his treatise on the three laws of motion the “Principia Mathematica Philosophiae Naturalis.” A fundamental insight was that (law #3) for every action in nature there is an equal and opposite reaction. For our current purposes with RLbF, a corollary is proposed to this physical law: when object ‘AI’ exerts a force on object ‘Brain,’ then object ‘Brain’ also exerts a force on object ‘AI.’
The software platform we use for exploration and testing related to this topic, ‘Isaac’ (Arctop Inc., 2026, v1.15. https://arctop.com/), implements a dual-agent architecture: an AI conversation agent that speaks with the human user, plus an AI recommendation agent that interprets cognitive state patterns from the human and advises the AI conversation agent, serving as a simulacrum of sorts for human neurobiologically-emergent and felt ‘empathy.’
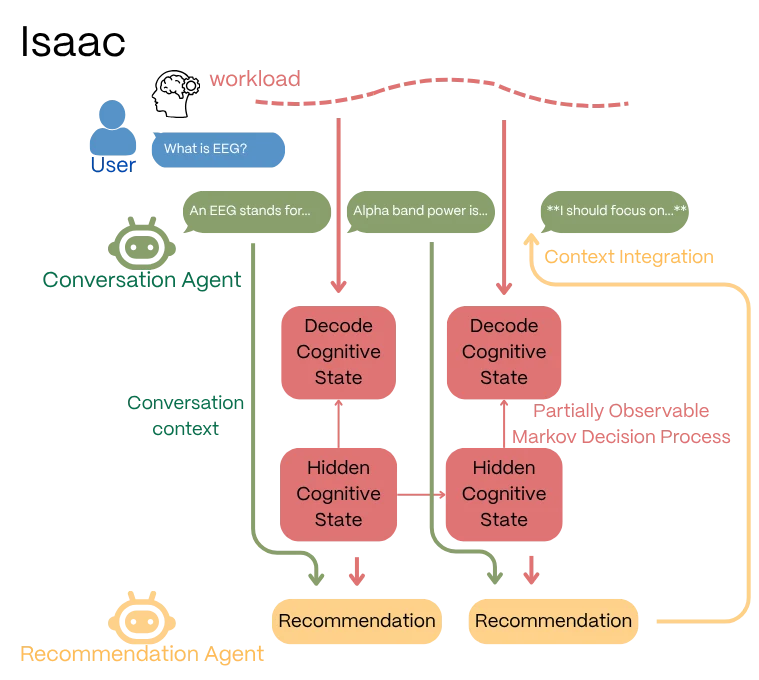
The CognitiveTracker buffers scores, detects significant shifts, and computes trends. The RecommendationAgent generates natural language advisories (e.g., “Workload has risen sharply. Consider simplifying your next response.”). The StreamController manages sentence-level delivery. The SessionRecorder captures timestamped interaction data for RLbF training. This dual-agent pattern is a deliberate stepping stone and future versions follow several distinct branches to help flesh out the best architectures for this structure of contextual data.
It is critical to distinguish Isaac’s current proof-of-concept architecture from the final RLbF-trained model. The dual-agent structure is a prompt-based scaffolding designed to bypass the need for architectural modifications to the base LLM during initial data collection. By translating continuous cognitive scores into natural language advisories, the Recommendation Agent allows an off-the-shelf instruction-tuned model to simulate empathic adaptation. However, this is a transitional architecture. In the fully realized Phase 3 RLbF model, the policy is optimized directly against the mathematical, three-component reward (Rtotal). At that stage, the LLM internalizes the cognitive state mappings into its weights, rendering the Recommendation Agent obsolete for real-time inference and resulting in a lower-latency, single-agent system.
4.2 Signal Processing Engineering
Isaac’s signal-processing layer instantiates the abstract requirements defined in Section 3 with specific, modular engineering choices. For the baseline normalization in Section 3.1, Isaac estimates the slowly varying baseline sdrift(τ) as a 60-second moving average of the cognitive state signal, subtracted from the raw scores before reward computation and predictor training. This window is long enough to average out utterance-scale fluctuations but short enough to track fatigue and habituation drift. For the temporal integration weighting w(τ; t) in Eq. 2, Isaac uses a trapezoidal window with ramp-up and ramp-down periods, which avoids sharp boundary artifacts while remaining simple to implement; a truncated Gaussian centered at δt + Δ/2 is a principled alternative. Both choices are modular: the framework accommodates different baseline estimators and window shapes, and Section 9.3 details known limitations of linear-subtraction detrending that motivate more sophisticated transfer-learning approaches in future work.
4.3 Cognitive Tokenization via Prompt Injection
We recommend natural language injection as the primary tokenization strategy: cognitive state is injected as a natural language string (e.g., “Cognitive workload: 0.85 (high – approaching overload)”) into the LLM’s context between sentences. This requires no architectural modifications, preserves full numerical precision, supports transparency (the injected text is human-readable for auditing), and works with any instruction-tuned model. Learned embeddings are the principled long-term optimization for production systems, but natural language injection is preferred for the research phase.
4.4 Voice Mode vs. Text Mode
The architecture supports two delivery modalities with different temporal dynamics. Voice mode introduces TTS latency (200–800ms per sentence), fixed delivery rate (~150 words/min), and auditory processing dynamics where the auditory focus dimension is directly informative. Text mode eliminates TTS latency but introduces variable reading speed (200–400 words/min) and self-paced processing, making temporal alignment less precise. The LLM uses the same weights for both modalities; modality-specific adaptation is learned during RLbF training from interaction data, not hard-coded. A modality parameter affects the cognitive state tokenizer (labeling which dimensions are relevant), the stream controller (switching delivery mechanism), and the delay model parameters.
4.5 Individual Calibration
Users differ in baseline cognitive state patterns, cognitive responses to language, and processing speed. A brief calibration session (estimated at 5–10 minutes) at first interaction establishes individual baselines (resting-state measurement), response characteristics (controlled stimuli eliciting known cognitive patterns), and conversational processing speed. Two adaptation strategies are supported: a few-shot cognitive profile injected as natural language into the system prompt (default for new users), and lightweight parameter adaptation (LoRA – Low-Rank Adaptation; Hu et al., 2022 – of the transition predictor) for returning users with accumulated data.
4.6 Inference Modes
Both closed-loop (with EEG) and open-loop (without EEG) modes use identical model weights. The only difference is the source of cognitive state: observed scores from the Arctop decoder in closed-loop mode, or predicted scores from the internal transition predictor fϕ in open-loop mode. The cognitive state tokenizer checks whether an Arctop score stream is available; if yes, it uses observed scores; if no, it queries the internal predictor. The model does not know which source is providing the scores – it receives the same natural language injection format in both cases. This design enables smooth transitions between modes, including mid-session device removal, and makes trained empathic capabilities available to users without EEG hardware.
The Isaac platform described above provides the runtime infrastructure; what remains is the training procedure that transforms a standard instruction-tuned LLM into a model capable of exploiting this infrastructure for empathic communication.
5. Training Pipeline
The pipeline is designed to transform a standard instruction-tuned LLM into a model that natively understands and responds to real-time cognitive state signals through three phases of increasing complexity. Phases 1 and 2 use Isaac’s prompt-injected dual-agent scaffolding (Section 4) to generate and collect training data; Phase 3 then trains a single pure RLbF policy that replaces the scaffolding and natively optimizes against the reward math defined in Section 3.
5.1 Phase 1: Supervised Fine-Tuning for Cognitive State Comprehension
Phase 1 teaches the model to parse cognitive state injections and adjust communication style accordingly. This phase is necessary because standard instruction-tuned LLMs have no prior exposure to cognitive state tokens; without supervised grounding, the model would treat injected scores as noise rather than actionable context, undermining the reward signal in subsequent phases.
Synthetic data is generated through three layers. Template-based generation defines cognitive state profiles (overwhelmed, productively challenged, bored, in-flow, stressed-but-coping, relaxed) with expected communication adaptations grounded in the resonance reward’s target functions. LLM-augmented variation expands coverage to thousands of diverse (conversation, cognitive_state, response) triples, ensuring that the model encounters cognitive state signals across a broad range of topics, registers, and conversational depths. Isaac advisory bootstrapping grounds the synthetic distribution in real cognitive state patterns from existing session logs, mitigating the risk that purely synthetic data teaches the model to respond to cognitive state profiles that do not occur in practice.
Success criteria include cognitive state parsing accuracy (>85% agreement with an LLM judge), measurable style adaptation (information density decreasing by at least 15% under high workload), appropriate comprehension check insertion, and no degradation of general conversational quality (within 5% on standard benchmarks). Estimated data requirements: 15,000–25,000 training examples (these figures are preliminary estimates pending empirical calibration).
5.2 Phase 2: Prediction Calibration with Real EEG Data
Phase 2 solves the hardest technical challenge: learning to predict how utterances affect cognitive state from real Isaac session recordings. This is the phase that grounds the framework in empirical reality – the transition from synthetic cognitive state profiles (Phase 1) to measured human cognitive responses. Its success determines whether the prediction accuracy reward (Rpred) and the open-loop inference mode (Section 4.6) are feasible: if the predictor cannot learn meaningful dynamics from real data, neither the reward signal nor the open-loop transfer hypothesis has a foundation.
An extraction pipeline processes raw recordings through sentence-level segmentation, drift detrending (60-second moving average subtraction), pre-utterance state measurement, post-utterance windowed aggregation, and quality filtering, producing aligned (ct, st, ut, st+1) tuples. Conservative temporal attribution truncates observation windows at the onset of subsequent utterances to prevent cross-sentence contamination. Quality filtering discards turns where EEG signal quality falls below a per-channel threshold or where the temporal gap between utterance delivery and state measurement falls outside the delay model bounds (Eq. 1), ensuring that the training set contains only reliably attributed cognitive state transitions.
The transition predictor fϕ is trained on these tuples with population-level user embeddings that capture individual variation within a single model. Success criteria include per-dimension prediction correlation exceeding 0.3 for at least 3 of 5 dimensions on held-out users, outperforming the no-change baseline by at least 15%, and an autoregressive open-loop horizon exceeding 10 turns. We estimate the minimum data requirements to perform this sufficiently to be: 250–500 sessions from 30 unique and unrelated EEG-equipped users.
A significant challenge in predicting cognitive state transitions from text is the problem of temporal credit assignment: isolating which specific tokens within an utterance evoked which specific neurological response. Human cognitive states do not shift in response to structural filler words (e.g., ‘the’, ‘is’), but rather have their own unique timescales that anchor to semantically salient or high-arousal tokens. To solve this, we leverage the natural language logs generated by the Isaac Recommendation Agent during Phase 1 data collection. The Recommendation Agent’s historical advisories serve as a semantic mask during Phase 2 predictor training. By aligning the system’s structural understanding of high-impact words with the recorded temporal delays, the predictor learns to ignore syntactic filler and attribute cognitive state changes specifically to the high-arousal tokens within the context window. This prevents the model from smearing the predicted cognitive response uniformly across an entire sentence.
5.3 Phase 3: Reinforcement Learning with Empathic Reward
Phase 3 is the step at which the model leaves the Isaac scaffolding behind. In Phases 1 and 2 the target model sits inside Isaac’s prompt-injected dual-agent loop (Section 4.1), receiving RecommendationAgent advisories as part of its context. In Phase 3, PPO trains the model to operate as a single policy that reads the cognitive-state injection directly and natively optimizes against the reward math in Section 3, with the RecommendationAgent retained only at training time (as the semantic mask for the Phase 2 predictor, §5.2) and absent at inference.
Phase 3 optimizes the policy using Proximal Policy Optimization (PPO; Schulman et al., 2017) against the full reward function:
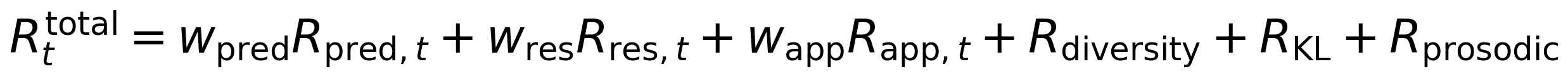
with the Phase 1 SFT (Supervised Fine-Tuning) model as the starting and reference policy and the Phase 2 prediction model providing Rpred.
We choose PPO over the DPO family (Rafailov et al., 2023) based on a specific analysis of RLbF’s requirements, not a generic preference. The DPO landscape has evolved substantially: KTO (Ethayarajh et al., 2024) eliminates the need for pairwise preference data by optimizing against a per-example utility function, online iterative DPO variants (Guo et al., 2024; Xu et al., 2024) address the original algorithm’s offline limitation, and reward-weighted regression methods can handle continuous reward signals. These advances make DPO-family methods viable for a wider range of alignment problems than the original formulation allowed. Nevertheless, three properties of the RLbF setting specifically favor PPO:
First, RLbF’s reward is a composite of six components (Rpred, Rres, Rapp, Rdiversity, RKL, Rprosodic) with different scales, noise characteristics, and update frequencies. PPO’s learned value function (which estimates expected future reward from a given state) can internalize the relative scaling and variance of these components, enabling stable optimization against the composite signal. DPO-family methods would require collapsing this structure into a single scalar or pairwise ranking before optimization, losing information about which reward components drive each comparison.
Second, the prediction model fϕ continues to update during Phase 3 as the policy generates novel utterances that fall outside the Phase 2 training distribution. This creates a non-stationary reward landscape where online exploration – generating utterances, observing their predicted cognitive effects, and updating the policy – is essential. PPO’s on-policy sampling (generating new training data from the current policy rather than reusing old data) naturally supports this co-evolution of policy and reward model. While online DPO variants address the static-dataset limitation of the original algorithm, they still optimize against pairwise preference rankings rather than directly against a continuous, multi-dimensional reward signal that itself evolves during training.
Third, RLbF requires credit assignment across sentence boundaries: a single utterance’s cognitive impact unfolds over a temporal window (Section 3.2), and the reward signal reflects the cumulative effect of multiple conversational turns on cognitive state trajectories. PPO’s value function learns to estimate long-horizon returns, enabling credit assignment (determining which earlier actions caused later outcomes) that connects current utterance choices to downstream cognitive outcomes. This temporal credit assignment problem does not map naturally onto the pairwise comparison framework that underlies DPO and its variants, including KTO’s per-example formulation.
The training supports both online (live Isaac sessions with real-time EEG) and offline (replaying Phase 2 session recordings with the prediction model) modes. In offline mode, the prediction model estimates cognitive state transitions for policy-generated utterances that differ from the recorded ones, introducing distributional shift (the mismatch between the training data distribution and the data the current policy generates) that limits the extent of offline optimization. A hybrid approach – offline pre-optimization to get a reasonable policy, followed by online fine-tuning with live EEG feedback – is recommended to balance data efficiency with the correction that real interaction provides. The recommended three-stage sequence and its performance-based transition criteria are:
- Offline RL warm-up (1–2 epochs over Phase 2 recordings): Establishes a baseline policy using conservative reward estimation.
- Hybrid online/offline (iterative): Short online sessions (15–30 minutes) with EEG-equipped users, combined with continued offline training. Gradually shifts the data distribution toward on-policy.
- Full online RL: Standard PPO training with live interaction for final optimization.
Transition criterion: offline to hybrid. Advance from offline-only to hybrid training when the offline-trained policy achieves Rres ≥ 1.10 × RresSFT (at least 10% improvement in resonance reward over the Phase 1 SFT baseline) on a held-out set of Phase 2 recordings, AND the mean estimated reward R̂total has plateaued (less than 2% relative improvement over the preceding 500 gradient steps). The first condition ensures the policy has learned nontrivially from offline data; the second ensures that offline returns are saturating and further improvement requires on-policy data.
Transition criterion: hybrid to full online. Advance from hybrid to full online training when two conditions hold: (1) the per-dimension prediction correlation of fϕ on the most recent online session batch meets or exceeds the Phase 2 baseline threshold (r ≥ 0.3 for at least 3 of 5 cognitive dimensions), confirming that the co-trained prediction model has adapted to the evolving policy distribution; and (2) the ratio of online-to-offline reward diverges by less than 10%, i.e., |Ronline − R̂offline| / Ronline < 0.10, indicating that the offline reward estimates have become unreliable enough that continued offline training adds diminishing value. At this point, the policy is stable enough for sustained live interaction and the reward signal quality justifies full online operation.
The KL divergence penalty coefficient βKL may require higher values (0.05–0.2) than typical RLHF settings because the cognitive state reward signal is noisier than human preference judgments. Training is monitored continuously for reward hacking indicators (Anthropic, 2025; Fu et al., 2025):
- Prosodic convergence
- Semantic diversity collapse
- Complexity collapse
- Question frequency spikes
- Warmth saturation
The specific values of constraint hyperparameters – including βKL, the diversity penalty weight, and the prosodic diversity coefficient are not fixed a priori but are to be calibrated empirically during Phase 3 training. Initial ranges are informed by the RLHF literature and the noise characteristics of EEG-derived reward, but final values should be determined through hyperparameter search on a validation set of held-out session recordings, with the reward hacking indicators above serving as diagnostic criteria for under- or over-regularization.
6. Open-Loop Empathic Transfer
Terminological note: In this section, we use “agent” in the decision-theoretic context (the POMDP actor) and “model” when discussing the underlying LLM; these refer to the same system.
6.1 The Hypothesis
The open-loop transfer hypothesis determines whether RLbF is a general-purpose training methodology or a niche technique for BCI users: does the benefit of brain feedback training persist when the EEG signal is removed at inference?
Formally, letting πRLbF denote the RLbF-trained policy and πRLHF denote a standard RLHF-trained policy from the same base model, the hypothesis claims that in open-loop deployment (no EEG):
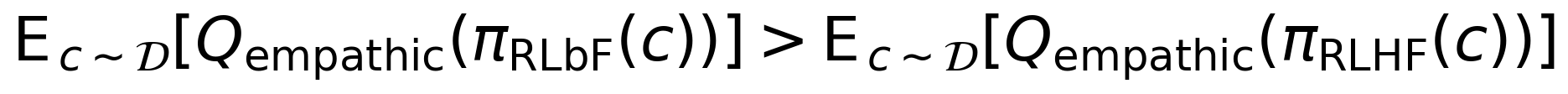
where Qempathic is a composite empathic quality measure and 𝒟 is the evaluation task distribution. If true, RLbF becomes a general training methodology: train with brain feedback on a moderately sized population, deploy without brain feedback to all users. If false, RLbF is limited to closed-loop applications.
This claim is a hypothesis, not a demonstrated result. The experimental design below (Section 7.4) specifies the falsification criterion for Eq. 7.
6.2 Theoretical Grounding
Three independent perspectives support the hypothesis. First, the Arctop synthetic brain model (Furman and Kwalwasser, US20210390366A1) demonstrates in commercial deployment that models trained on paired (content, neural) data can predict from content features alone – the neural features serve as privileged information (Vapnik and Vashist, 2009; Lopez-Paz et al., 2016) during training. Second, RLHF generalization research shows that models trained with preference feedback generalize beyond their reward distribution (Kirk et al., 2024), and RLbF’s richer reward signal (Section 1.2) may provide favorable conditions for at least comparable generalization. Third, cognitive science research on theory of mind (ToM) (Premack and Woodruff, 1978; Baron-Cohen, 1995), including simulation theory accounts of mindreading (Gallese and Goldman, 1998; Goldman, 2006), shows that skilled human communicators develop internal models of their interlocutors through rich multimodal feedback, then apply these models effectively in feedback-impoverished settings.
6.3 Two Levels of Transfer
We distinguish style transfer (Level 1, likely) from state inference (Level 2, aspirational). At Level 1, the model has internalized population-level regularities about what kinds of language produce what kinds of cognitive responses – adaptive information density, emotional calibration, engagement preservation, comprehension checking. At Level 2, the model infers specific users’ cognitive states from conversational cues alone. Level 1 is the conservative claim; Level 2 requires the model to develop a genuine computational theory of mind and remains a research goal.
A caveat is warranted regarding the ToM analogy. Whether LLMs can develop genuine theory of mind – as opposed to surface-level behavioral mimicry of mentalizing – is scientifically contested (Ullman, 2023), and claims of emergent ToM in large models have faced significant methodological criticism. This debate bears directly on the plausibility of Level 2 transfer, which depends on the assumption that an LLM can learn to infer individual cognitive states from conversational cues in a manner analogous to human mentalizing. Level 1 transfer, by contrast, requires only that the model acquire statistical regularities between language patterns and population-level cognitive responses, a form of distributional learning that does not presuppose ToM. We therefore regard Level 2 as the more speculative claim in the framework and flag it as dependent on assumptions that remain open questions in the field.
6.4 The Sycophancy Counterargument
The most important counterargument is that the model has learned to be generically “nicer” rather than genuinely adaptive, producing warmer, simpler responses without sophisticated context-dependent adaptation. We identify this as “neurological sycophancy”: the displacement of deliberative sycophancy to the neural level, where the model optimizes for brain pleasure signals rather than genuine communicative benefit. Five ordered diagnostic tests are designed to distinguish empathic adaptation from generic niceness:
- Context-dependent complexity modulation
- Appropriate challenge (correcting errors despite comfort cost)
- Information density adaptation to inferred expertise
- Emotional specificity across different negative emotions
- Cognitive state trajectory prediction accuracy
6.5 Experimental Design
The open-loop transfer hypothesis is empirically testable through a controlled comparison of models trained with and without brain feedback, evaluated with and without EEG at inference. The experimental logic requires four conditions from the same base model: a Baseline LLM (no post-training), an RLHF-trained control (same base model fine-tuned with standard RLHF, isolating the post-training signal as the sole variable), an RLbF-trained closed-loop ceiling condition, and the critical test: an RLbF-trained model deployed open-loop (without EEG). The critical comparison is open-loop RLbF versus RLHF: if the open-loop RLbF model demonstrates superior empathic quality despite having no access to EEG at inference, this constitutes evidence that brain feedback training produces durable communication skills. Section 7.4 specifies the full experimental protocol, including the within-subjects Latin square design, sample size justification, statistical tests, and confound controls.
7. Roadmap to Empirical Validation
Our proposed evaluation framework is organized into four tracks, each targeting a different category of claims to be empirically tested. The protocol is specified at pre-registration quality: with each metric, statistical test, baseline, and sample size defined with enough detail for reproducibility. The protocol distinguishes pilot evaluations (feasible with current Isaac data, suitable for arXiv) from full evaluations (requiring dedicated recruitment, journal submission).
7.1 Track A: Prediction Accuracy
This track evaluates whether the cognitive state predictor fϕ learns useful dynamics of how language affects cognition. The test set comprises held-out Isaac sessions with strict user-level partitioning: no user appears in both training and test sets. The primary evaluation uses leave-one-user-out cross-validation across a minimum of 30 unique users, ensuring that prediction accuracy reflects generalization to new individuals rather than memorization of user-specific patterns.
Metrics include per-dimension mean absolute error (target: MAE < 0.10 on the [0,1] scale, representing the perceptual boundary between comfortable and effortful processing, and a meaningful improvement over the expected persistence-baseline MAE of approximately 0.12), Pearson correlation between predicted and observed cognitive state transitions (target: r > 0.5, anchored to the EEG-based affect recognition literature where models typically achieve r = 0.4–0.7; Koelstra et al., 2012), and change-based Δ-MAE (target: < 0.08). Four baselines establish the performance floor: random prediction, population mean, persistence (predicting no change), and linear regression on hand-crafted utterance features (token count, GPT-2 surprisal, VADER sentiment). Users contributing fewer than 3 sessions are excluded from the k-fold cross-validation to ensure sufficient within-user data. An open-loop accumulation test further assesses whether prediction accuracy degrades gracefully over multi-turn conversations or exhibits compounding error drift.
7.2 Track B: Self-Report Validation
This track validates perceived empathic quality and establishes convergent validity between self-report and EEG-derived measures. Four adapted instruments capture complementary constructs: the Working Alliance Inventory (WAI-SR) measures perceived rapport and collaboration, the Interpersonal Reactivity Index empathic concern subscale (IRI-EC) measures perceived empathy, the NASA Task Load Index (NASA-TLX) measures perceived cognitive demand, and a custom 5-item RLbF Adaptation Perception Scale measures perceived responsiveness to the participant’s cognitive state.
The WAI-SR and IRI-EC were originally validated for human-human therapeutic interaction (Hatcher and Gillaspy, 2006; Davis, 1983); early work adapted the WAI-SR for human-agent interaction (Bickmore et al., 2005), but psychometric properties of these instruments in modern human-AI contexts remain an open empirical question. Assessing construct validity, internal consistency, and factor structure of the adapted instruments is therefore a planned component of this study’s pilot phase, rather than an assumed given. Self-report vs. EEG correlations test ecological validity across five pre-specified dimension pairs (e.g., NASA-TLX Mental Demand vs. mean session workload, target: r > 0.30; IRI-EC vs. mean enjoyment trajectory slope). These thresholds are grounded in published EEG-self-report correlation data: NASA-TLX vs. EEG workload indices typically achieve r = 0.3–0.6 (Wobrock et al., 2015; Kamzanova et al., 2014), while EEG-affect vs. self-report correlations are typically lower (r = 0.15–0.35; Koelstra et al., 2012). Holm-Bonferroni correction is applied across the 5 convergent validity tests to control the family-wise error rate.
7.3 Track C: Cognitive Trajectory Analysis
This track tests whether RLbF-trained models produce measurably different cognitive state trajectories compared to non-adaptive baselines. Rather than evaluating single-turn responses, Track C examines the temporal dynamics of entire conversations, capturing how the model’s adaptive behavior shapes cognitive experience over multi-turn interactions.
Four trajectory-level metrics are computed for each session: cognitive state stability (variance of each dimension relative to the baseline condition reference variance), recovery speed from overload and stress episodes (time to return below a per-dimension threshold after exceedance), trajectory coherence (mutual information between utterance features and subsequent cognitive state changes, estimated via the Kraskov k-nearest-neighbors estimator with k = 5; Kraskov et al., 2004), and cumulative time in the productive zone. The productive zone is defined per dimension (e.g., workload between 0.30 and 0.75, stress below 0.60) based on Cognitive Load Theory thresholds where learning and engagement are optimized.
7.4 Track D: Open-Loop Transfer A/B Test
This track provides the definitive test of the open-loop transfer hypothesis (Section 6.1, Eq. 7) through a controlled within-subjects comparison of four conditions from the same base model: Baseline LLM (no post-training), RLHF-trained (same base model fine-tuned with standard RLHF on a general preference dataset, isolating the post-training method as the sole variable), RLbF-trained closed-loop (ceiling – full EEG feedback during interaction), and RLbF-trained open-loop (the critical test – brain-feedback-trained model deployed without EEG). The EEG device actively records data in all four conditions; only the real-time data feed to the model varies (see evaluation protocol for details). To achieve the target of 60 completers (15 full Latin squares of 4 conditions), 70 participants are recruited to account for an estimated 15% attrition rate. Each participant completes four 35-minute conversational sessions across different topics drawn from a standardized pool with random assignment.
Eight pre-registered hypotheses are tested with repeated-measures ANOVA. Directional hypotheses (H1–H5, H7) are tested with one-tailed paired t-tests, as the predicted direction is specified a priori and the reverse direction is not theoretically meaningful. Hypotheses H1–H4 and H7–H8, which test closed-loop RLbF superiority over baselines, form one correction family (6 pairwise comparisons) with Holm-Bonferroni correction. The critical open-loop transfer hypothesis – that open-loop RLbF outperforms RLHF on the composite empathic quality measure – is tested as a separate, pre-registered primary hypothesis at α = 0.05 (uncorrected). This separation is justified because the open-loop comparison tests a conceptually distinct claim (whether brain-feedback training produces durable skills that transfer without EEG at inference) from the closed-loop superiority hypotheses (whether real-time EEG feedback improves communication quality). Testing it within the closed-loop family would penalize the study’s most novel claim for sharing a correction family with hypotheses it neither depends on nor competes with.
The open-loop comparison is powered at 80% to detect a small-to-medium effect of d = 0.37 (paired t-test, α = 0.05 two-tailed, assumed within-subject correlation r = 0.5, yielding N = 60). The d = 0.37 target represents the minimum practically meaningful improvement over RLHF – the smallest effect that would justify the additional infrastructure cost of brain-feedback training (EEG data collection, cognitive state decoding, and the multi-phase training pipeline) over standard preference-based alignment. This threshold is grounded in three considerations. First, meta-analyses of empathic communication interventions in therapeutic and educational settings report effect sizes of d = 0.3–0.6 for perceived empathy differences (Horvath and Symonds, 1991; Bickmore et al., 2005), placing d = 0.37 at the lower bound of the range where empathic quality differences become reliably perceptible to recipients. Second, the RLHF alignment literature reports effect sizes of d = 0.4–0.8 for preference-trained models over base models on human evaluation metrics (Ouyang et al., 2022; Stiennon et al., 2020); a d = 0.37 improvement of RLbF-OL over RLHF thus represents a conservatively meaningful increment beyond standard alignment. Third, in practical terms, d = 0.37 on the productive time proportion scale corresponds to approximately 4–5 additional minutes per 35-minute session spent in the cognitive productive zone – a difference large enough to have pedagogical or therapeutic significance in sustained conversational interaction. To assess sensitivity to this assumption, Figure S1 in the supplementary materials reports a power curve showing the required N for effect sizes ranging from d = 0.2 to d = 0.5: at d = 0.2, N = 199 would be required; at d = 0.3, N = 90; at d = 0.5, N = 34. The chosen N = 60 provides 80% power at d = 0.37 and retains 65% power even if the true effect is as small as d = 0.30.
TOST (Two One-Sided Tests) equivalence testing determines whether open-loop performance falls within a pre-specified equivalence bound (Δ = 0.10 on productive time proportion) of the closed-loop ceiling. The Δ = 0.10 margin represents the meaningful-difference boundary: it is approximately half the expected RLbF-CL advantage over BASE, following the standard practice of setting equivalence margins at half the expected treatment effect (Lakens, 2017), and a degradation beyond this threshold would place open-loop performance below the expected RLHF level, negating the practical case for brain-feedback training. Measures span blind human evaluation of response quality, cognitive metrics from EEG (collected in all conditions but fed to the model only in the closed-loop condition), and participant self-report using the instruments from Track B. Bayes factors (BF10) are reported for all significant results using the default JZS prior with scale parameter r = 0.707 (Rouder et al., 2009). Confounds are addressed through counterbalancing (novelty effects), sham EEG with active recording in all conditions (Hawthorne effects), EEG signal quality covariates, the standardized topic pool (topic effects), restricted scheduling within a 10:00–16:00 window with within-participant time consistency (fatigue and circadian effects), automated condition assignment with experimenter blinding (experimenter bias), and a post-study manipulation check assessing whether participants identified the adaptive condition (demand characteristics).
The evaluation protocol specifies how to measure RLbF’s claims; equally important is whether those claims should be pursued at all. Deploying a system that monitors and responds to users’ cognitive states raises ethical questions that must be addressed as part of the framework design, not deferred to post-deployment review.
8. Ethical Framework
Our ethical analysis is positioned within two established frameworks for neurotechnology governance.
Yuste et al. (2017) proposed four ethical priorities for neurotechnologies and AI (privacy, identity, agency, and equality) in a landmark Nature commentary from the Morningside Group. RLbF engages three directly: privacy through on-device data minimization (Section 8.3), agency through user control safeguards and the empathic/persuasive distinction (Sections 8.1, 8.4), and identity through autonomy protections against long-term communicative shaping. The equality priority – ensuring cognitive enhancement technologies do not exacerbate existing inequalities – remains an open policy challenge not addressed by architectural safeguards alone.
Independently, Ienca and Andorno (2017) articulated four fundamental ‘neurorights’ to protect individuals’ mental processes from unauthorized access, manipulation, or discrimination by neurotechnology: cognitive liberty, mental privacy, mental integrity, and psychological continuity. These rights have since influenced Chile’s constitutional neurorights amendment and a 2023 Chilean Supreme Court ruling on neural data protection (Cornejo-Plaza et al., 2024). The RLbF consent framework (Section 8.3) maps to cognitive liberty and mental privacy; the empathic/persuasive boundary (Section 8.1) addresses mental integrity; and the autonomy safeguards (Section 8.4) protect psychological continuity.
The UNESCO Recommendation on the Ethics of Neurotechnology (UNESCO, 2025) provides a third governance reference point. Two provisions are particularly relevant to RLbF. First, the Recommendation’s principle of mental privacy – that neural data should be afforded protections at least equivalent to those for health data and that individuals retain the right to control access to information derived from their brain activity – is directly implemented by RLbF’s on-device data minimization architecture, which ensures that raw EEG never leaves the acquisition device and that only derived cognitive state scores are transmitted (Section 8.3). Second, the Recommendation’s emphasis on cognitive liberty – that neurotechnologies must not be used to manipulate individuals’ mental processes without their free and informed consent – maps to the empathic/persuasive boundary formalized in Section 8.1 and the consent requirements that mandate disclosure of all reward function objectives.
8.1 Empathic vs. Persuasive Computing
A system that reads cognitive signals and modifies its behavior raises fundamental questions about manipulation and autonomy. We define empathic computing as a paradigm where the system adapts to the user’s cognitive state without driving that state toward a predetermined target; the user’s state is the input, not the target. Persuasive computing (Fogg, 2003) uses cognitive state knowledge to drive the user toward an external goal (maximizing engagement, inducing purchases). Three testable criteria distinguish the paradigms: the presence of a target state, the direction of optimization (system behavior vs. user state), and the disclosure of objectives.
The default RLbF configuration (wapp = 0) eliminates application-layer goals. However, we must be precise: Rres still encodes normative assumptions about desirable communication dynamics (manageable workload, reduced stress, maintained focus). These internally encoded communication-quality goals are defensible as beneficent defaults but are still goals. More precisely, wapp = 0 precludes externally imposed goals while retaining internally encoded goals about communication quality. This is the difference between “the system helps you process information” and “the system drives you toward a behavior” – a meaningful distinction that should not be overstated. It should also be noted that the default communication-quality targets embedded in Rres – what constitutes manageable workload, appropriate emotional tone, and desirable information density – are culturally and contextually contingent; norms for directness, cognitive challenge, and affective expression vary across cultures, professional domains, and individual preferences, and deployments outside the training population’s cultural context may require recalibration of these defaults.
A deeper philosophical complication arises from the prediction model fϕ. Criterion 2 claims that an empathic system optimizes the system’s behavior rather than the user’s state. However, fϕ is trained to predict cognitive state transitions: ŝt+1 = fϕ(ct, st, ut). In learning this mapping, fϕ necessarily acquires a model of the causal chain from utterance properties to cognitive state changes — it learns which utterance features produce which cognitive effects. During RL training, the policy πθ uses fϕ’s predictions to select utterances that maximize Rres, which is a function of the predicted next cognitive state. The optimization is formally over the policy’s action space (word choice, pacing, information density), but the reward gradient flows through a learned model of user state dynamics. The system is, in effect, selecting actions for their predicted effects on the user’s cognitive state, even though the optimization variable is the system’s output rather than the user’s brain. This is analogous to the distinction between a thermostat – which “optimizes its behavior” by adjusting heating output but does so precisely to change room temperature – and a device that targets temperature directly. The empathic/persuasive boundary therefore rests not on whether the system models user state consequences (it necessarily does) but on whether the system pursues an externally imposed target state versus adapting to the user’s current state without a predetermined destination. We regard this as an honest complication rather than a fatal objection: the Criterion 2 claim should be understood as “the system adapts its behavior in response to user state” rather than the stronger and less defensible “the system has no model of how its behavior affects user state.”
8.2 Informational Power Asymmetry
A fundamental informational asymmetry exists – one that raises neurorights concerns (Yuste et al., 2017; Ienca and Andorno, 2017): the model has real-time access to the user’s cognitive state while the user has no reciprocal access to the model’s strategy. This asymmetry persists even under transparency safeguards, because the model has an integrative advantage (processing scores across time at token-generation speed), a training advantage (learned patterns from thousands of interactions), and a speed advantage (adaptation occurs before the user is consciously aware). Transparency (the user can see their data) is achievable and necessary; full symmetry (equivalent understanding of interaction dynamics) is not achievable. We propose mitigations – real-time adaptation explanations, model-state disclosure, periodic asymmetry audits, and a right to cognitive opacity – while acknowledging that the asymmetry is a permanent structural feature.
Critically, the informational asymmetry is not static: it grows with model capability and accumulated training data. As the model is trained on more interaction sessions, its training advantage deepens since it has observed a wider range of cognitive response patterns and learned subtler correlations between utterance features and cognitive state transitions. As model architectures become more capable (larger context windows, more expressive policy networks), the integrative advantage strengthens, and the model can exploit longer temporal dependencies in cognitive state trajectories that no human interlocutor could track. This scaling dynamic means that the mitigations proposed above are not a one-time implementation but a continuously evolving requirement: the strength of transparency safeguards, the granularity of adaptation explanations, and the frequency of asymmetry audits should scale proportionally with the model’s informational advantage. A deployment that was ethically adequate at one capability level may become inadequate after further training or architectural improvement. We therefore recommend that any RLbF deployment include a capability-proportional safeguard policy that triggers reassessment of mitigation adequacy whenever the model undergoes significant retraining or capability expansion.
8.3 Mental Privacy and Consent
EEG data is not like behavioral clickstream data. It is an involuntary biological signal that reveals aspects of cognitive processing the user may not be aware of and cannot suppress. The RLbF architecture enforces a critical data minimization choice: raw EEG never leaves the device; only derived cognitive scores are transmitted. This irreversible transformation supports privacy while preserving the information needed for adaptation. It is designed to increase brain capital and the mental wealth of each individual user, not lessening either – thus consent must be specific (naming monitored dimensions), comprehensible, granular (allowing partial consent), revocable with immediate effect, and ongoing.
Critically, informed consent for RLbF systems should be dynamical and updated to include explicit risk disclosure, a requirement absent from many BCI research protocols and one that IRB review processes have not yet standardized for neurodata-based AI. The consent process must disclose, at minimum: (a) that the system learns patterns in the user’s cognitive responses and adapts its behavior accordingly, which may subtly shape the user’s communication expectations over time; (b) that the informational asymmetry described in Section 8.2 is a permanent structural feature, not a temporary limitation; (c) that long-term cognitive effects of sustained adapted communication are unknown and have not been studied longitudinally; and (d) that cognitive data decodings, while derived from validated models, are probabilistic inferences about internal states and are subject to incidental measurement error, individual variations, and biases in the underlying EEG models. These risk disclosures go beyond the standard IRB-required statement that “participation may involve unknown risks” and treats participants as intelligent, active co-creators with the specific information communicated to them in a way they understand, which is needed to make genuinely informed decisions about their sustained neurodata driven interactions.
Beyond risk disclosure, the consent framework also should address benefits, compensation, and injury provisions. Participants should be informed of the anticipated direct benefits of participation (e.g., exposure to communication adapted to their cognitive state, contribution to research on empathic AI) as well as the realistic possibility that no direct benefit may accrue, particularly in early-stage research where the system’s adaptive behavior may be unreliable or imperceptible. Compensation structures for research participants should be designed to avoid undue inducement while fairly valuing the time, cognitive effort, and neural data contributed; this is especially important given that EEG-based participation is more invasive and time-intensive than standard survey-based AI research.
Finally, the consent process must specify provisions for participant injury, including both physical harm (e.g., discomfort from prolonged EEG device wear, skin irritation from electrodes) and psychological harm (e.g., distress caused by the system’s maladaptive responses to misinterpreted cognitive states, or anxiety arising from awareness of continuous cognitive monitoring). Participants must be informed of available recourse, including procedures for reporting adverse experiences, access to appropriate clinical support, and the circumstances under which the research team will provide or facilitate medical or psychological care.
In multi-party settings, all participants (including non-monitored ones) must be informed that the model adapts to monitored users’ cognitive states, with transparent policies for priority resolution and opt-out mechanisms for non-monitored participants. An additional consent requirement arises when session recordings are used as training data (Phases 2 and 3): because multi-party interaction logs encode the communicative behavior and contextual contributions of all participants, consent for use in model training must be obtained from every participant in the session, not only those whose EEG was recorded.
Under the EU General Data Protection Regulation (GDPR), EEG-derived data such as cognitive workload, enjoyment, and focus constitute special category data within the meaning of Article 9, because they are inferred from biological signals and reveal information about an individual’s mental health and cognitive processing. Any RLbF deployment processing such data in jurisdictions subject to the GDPR must therefore obtain explicit consent under Article 9(2)(a), conduct a Data Protection Impact Assessment (DPIA) as required by Article 35 for high-risk profiling of sensitive data, and honor the data portability right under Article 20 by enabling users to export their cognitive state logs in a structured, machine-readable format.
Article 22 of the GDPR, which grants individuals the right not to be subject to decisions based solely on automated processing that produce legal or similarly significant effects, requires specific analysis in the RLbF context. An RLbF system that autonomously adapts its communication based on real-time cognitive state inference is engaged in automated decision-making about how to interact with the user – decisions that, in certain deployment contexts, could produce significant effects on the individual. In therapeutic settings, automated adaptation decisions could influence treatment outcomes; in educational contexts, they could affect learning trajectories and assessments; in employment-related communication, they could shape professional evaluations. While the adaptive communication decisions in a general conversational context may not rise to the level of “legal or similarly significant effects,” deployers must conduct a context-specific Art. 22 analysis for each use case. Where Art. 22 applies, the deployment must implement meaningful human oversight (not merely nominal human-in-the-loop), provide the user with information about the logic involved in the automated processing, and offer mechanisms to contest the automated decision and obtain human review. The RLbF framework’s existing transparency safeguards (adaptation explanations, model-state disclosure) provide a foundation for Art. 22 compliance, but they must be supplemented with explicit contestation mechanisms and genuine human oversight authority in high-stakes deployment contexts.
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) imposes specific obligations when RLbF is deployed in therapeutic or clinical contexts. Where an RLbF system is integrated into a healthcare provider’s services (for example, as a communication aid in teletherapy, cognitive rehabilitation, or mental health support) the cognitive state scores derived from EEG constitute protected health information (PHI) under HIPAA’s Privacy Rule (45 CFR Part 160 and Subparts A and E of Part 164). This classification triggers requirements including: designation of the RLbF platform operator as a business associate with an executed Business Associate Agreement (BAA); implementation of administrative, physical, and technical safeguards under the Security Rule (45 CFR Part 164, Subparts A and C); minimum necessary use limitations restricting cognitive state data access to the specific dimensions required for the therapeutic purpose; individual rights to access and amend their cognitive state records; and breach notification obligations within 60 days of discovery for unauthorized disclosure of cognitive state data. The on-device processing and score-only transmission architecture described above aligns well with HIPAA’s minimum necessary standard, but deployers must additionally ensure that cognitive state logs stored for longitudinal monitoring (Section 8.5) are encrypted at rest and in transit, that access controls restrict data to authorized clinical personnel, and that de-identification procedures meet HIPAA’s Safe Harbor or Expert Determination standards before any use in research or model training. Analogous obligations apply under other health-data regulations (e.g., the Personal Information Protection Law (PIPL) in China) and emerging neurotechnology governance frameworks (UNESCO, 2025; Cornejo-Plaza et al., 2024). Deployers should map the consent framework described above to the applicable regulatory regime before any user-facing trial.
In addition to essential data protections, the EU Artificial Intelligence Act (Regulation 2024/1689) introduces a risk-based classification framework with direct implications for RLbF deployment. An RLbF system is likely to be classified as high-risk under Annex III of the AI Act on at least two grounds. First, Category 1(a) covers AI systems intended to be used as safety components of, or that themselves constitute, biometric identification or categorization systems, and EEG-derived cognitive state inference may qualify as biometric categorization of natural persons based on physiological signals. Second, if RLbF is deployed in educational or vocational training contexts (Category 3) or in contexts that affect access to essential services (Category 4), the system falls squarely within the high-risk classification. High-risk classification triggers obligations under Title III, Chapter 2 of the AI Act: a risk management system maintained throughout the AI system’s lifecycle (Art. 9), data governance requirements including examination for possible biases in the training data (Art. 10), technical documentation sufficient for conformity assessment (Art. 11), record-keeping and automatic logging of system operation (Art. 12), transparency obligations including user-facing information about the system’s capabilities and limitations (Art. 13), human oversight provisions enabling human intervention and override (Art. 14), and accuracy, robustness, and cybersecurity requirements (Art. 15). Several of these requirements align with safeguards already proposed in the RLbF framework: the ethical review checklist (Section 8.4) addresses transparency and human oversight, and the data minimization architecture satisfies the spirit of data governance. However, conformity assessment, lifecycle risk management, and the specific technical documentation requirements of Art. 11 would require dedicated compliance infrastructure beyond what the current framework specifies. Deployers targeting EU markets should conduct a formal AI Act classification analysis and engage with the relevant national supervisory authority before any user-facing deployment.
8.4 Safeguards and Oversight
Architectural safeguards include user control (hard off-switch for adaptation, granular dimension controls, explicit preference overrides), no hidden objectives (disclosure and separate consent for any wapp > 0 deployment), and anti-sycophancy guardrails (diversity constraints, challenge injection, periodic baseline exposure). The risk that sustained adaptation may erode users’ capacity to process unadapted communication is a specific instance of cognitive offloading (Risko and Gilbert, 2016): when an external system reliably performs a cognitive function, individuals reduce their own investment in that function. Periodic baseline exposure is designed to counteract this tendency by maintaining the user’s independent communicative resilience.
We recommend that baseline exposure sessions – in which the system disables cognitive state adaptation and operates with standard, non-adapted output – occur at a minimum frequency of one session per five adapted sessions (or at least once per week for daily users), with each baseline session lasting at least 15 minutes of continuous interaction. Users must be permitted to opt out of baseline exposure; however, opting out should trigger a logged advisory, and sustained opt-out (more than four consecutive weeks) should be flagged for review by the deployment oversight body. The ethical review checklist for RLbF deployments covers:
- Reward function transparency – all reward components and weights are documented and accessible to auditors. Blocking: deployment must not proceed without published reward specification.
- Target state verification – formal confirmation that no externally imposed target cognitive state is encoded in the reward function (or, if wapp > 0, that the target is disclosed). Blocking.
- Data minimization – only derived cognitive scores (not raw EEG) leave the acquisition device. Blocking.
- User control – hard off-switch, granular dimension controls, and explicit preference overrides are functional and tested. Blocking.
- Consent adequacy – consent satisfies specificity, comprehensibility, granularity, revocability, and risk disclosure requirements (Section 8.3). Blocking.
- Anti-sycophancy measures – diversity constraints, challenge injection, and baseline exposure protocol are active and parameterized. Advisory: absence does not prevent deployment but triggers enhanced monitoring.
- Autonomy safeguards – baseline exposure schedule is implemented and opt-out logging is operational. Advisory.
- Human oversight for high-stakes contexts – a designated human reviewer is assigned for therapeutic, educational, or crisis-adjacent deployments. Blocking for high-stakes contexts; advisory otherwise.
- Asymmetry mitigations – real-time adaptation explanations and periodic asymmetry audits are scheduled. Advisory.
- Third-party consent – all non-monitored participants in multi-party settings have been informed and have opted in. Blocking for multi-party deployments.
- Implicit goal disclosure – internal communication-quality objectives encoded in Rres are documented and disclosed to users. Advisory.
- Incident response mechanism – a documented protocol exists for responding to adverse cognitive events (e.g., acute distress, unanticipated cognitive state patterns) detected during deployment, including escalation criteria and responsible parties. Blocking.
- Version control and re-consent – significant model updates (retraining, reward function modification, or architecture changes) trigger re-consent from active users and version-stamped audit logs linking each user session to the model version in use. Blocking.
- Acknowledgement that EEG is intrinsically Personally Identifiable Information (PII) data and that data handling must accordingly abide by all local, state and federal laws of the United States of America pertaining to Personally Identifiable Information. Blocking.
The strongest ethical case for RLbF is structural: wapp = 0 removes the mechanism for externally specified manipulative objectives. The strongest concerns are that implicit goals can produce harmful emergent behaviors (sycophancy, echo chambers, cognitive narrowing) and that informational asymmetry creates structural conditions for exploitation. The safeguards make risks visible and manageable, not absent.
Long-term cognitive effects. The attunement paradox described above – the risk that effective adaptation reduces the user’s own adaptive capacities – is an instance of the broader cognitive offloading phenomenon studied in cognitive psychology (Risko and Gilbert, 2016). When individuals routinely delegate cognitive tasks to external tools, the corresponding cognitive skills atrophy: GPS navigation erodes spatial reasoning, calculators diminish mental arithmetic, and spell-checkers weaken orthographic memory. RLbF’s communication adaptation constitutes cognitive offloading of the skill of parsing imperfect communication – a skill that is exercised in virtually every human interaction and whose erosion would have pervasive consequences. Three specific long-term effects warrant attention.
First, skill atrophy: sustained exposure to communication optimized for the user’s cognitive state may degrade the user’s capacity to extract meaning from communication that is poorly structured, ambiguously worded, emotionally mismatched, or delivered at an inappropriate level of complexity. This capacity is a foundational social skill, and its degradation would impair the user’s ability to function in unadapted human communication environments.
Second, communication expectation calibration: users habituated to cognitively attuned communication may develop expectations that human interlocutors cannot meet, leading to frustration, disengagement, or social withdrawal when interacting with non-adaptive conversation partners. This effect is analogous to the documented phenomenon of users developing unrealistic expectations of conversational quality after sustained interaction with AI assistants.
Third but not least, metacognitive effects: if the system’s adaptation is sufficiently seamless, users may lose awareness of their own cognitive state dynamics, including the effort of comprehension, the experience of confusion, the satisfaction of working through a difficult idea, because these experiences are managed away before conscious registration. This metacognitive flattening could impoverish the user’s self-understanding and reduce their capacity for self-directed cognitive regulation. The periodic baseline exposure safeguard partially addresses these risks, but its efficacy depends on implementation specifics that remain unresolved: the frequency and duration of baseline episodes, whether users can opt out (which would render the safeguard toothless), and whether brief periodic exposure is sufficient to prevent skill atrophy from sustained adapted interaction between exposures. Longitudinal studies measuring communication competence, interpersonal satisfaction in unadapted settings, and metacognitive awareness across sustained RLbF use are essential before any deployment beyond research contexts.
8.5 Vulnerable Populations
The ethical framework described above treats users as a homogeneous category, but certain populations face heightened risks from cognitive-state-adaptive AI systems and require population-specific safeguards.
Children and adolescents. Developing brains exhibit different EEG signatures than adult brains, and cognitive state models trained on adult populations may produce systematically inaccurate inferences when applied to minors (Saby and Marshall, 2012). More fundamentally, children and adolescents are in a formative period during which communication skills, cognitive resilience, and metacognitive capacities are actively developing. A system that adapts communication to minimize cognitive difficulty could interfere with the developmental processes through which young users learn to parse complex language, tolerate ambiguity, and engage with cognitively demanding material. Any RLbF deployment involving minors should require (a) age-appropriate recalibration of cognitive state models using pediatric EEG norms, (b) parental or guardian consent in addition to age-appropriate assent, (c) heightened baseline exposure requirements (Section 8.4) to protect developmental acquisition of communication skills, and (d) exclusion from any deployment with wapp > 0 pending dedicated ethical review.
Individuals with mental health conditions. Users experiencing depression, anxiety disorders, PTSD, or other mental health conditions present both the strongest use case and the greatest risk for empathic AI. On one hand, these users may benefit most from communication that is calibrated to their cognitive state: reduced information density during high-stress episodes, for example. On the other hand, their cognitive state signals may be atypical, their vulnerability to dependence on adapted communication may be elevated, and the boundary between empathic support and therapeutic intervention becomes blurred. RLbF systems must not be represented as therapeutic tools unless they have undergone clinical validation and regulatory review as medical devices. Deployments in contexts where users with mental health conditions are likely to be present, such as counseling platforms, crisis services, health information systems, should implement additional safeguards: clinical oversight by a licensed mental health professional, real-time monitoring for cognitive state patterns indicative of acute distress, and clear escalation protocols that route users to human care when the system detects states outside its competence boundary.
Neurodivergent users. Individuals with autism spectrum conditions, ADHD, dyslexia, or other neurodevelopmental differences may exhibit cognitive state patterns that diverge systematically from the population norms on which fϕ is trained. A model calibrated to neurotypical EEG patterns may misinterpret neurodivergent cognitive states: for instance, interpreting atypical attention patterns as disengagement when they reflect a different but functional mode of cognitive processing. This is not merely a measurement error problem but a normative one: the “desirable” cognitive state trajectory encoded in Rres reflects neurotypical assumptions about what constitutes manageable workload, appropriate focus, and reduced stress. Neurodivergent users may thrive under cognitive conditions that the system treats as suboptimal. Addressing this requires (a) explicit inclusion of neurodivergent users in training populations with distinct user embeddings, (b) user-configurable cognitive state targets that override population-level defaults, and (c) transparency about the normative assumptions embedded in the default reward function.
Elderly users and users with cognitive decline. Older adults, particularly those with early-stage cognitive decline or dementia, face a distinctive version of the attunement paradox: a communication-adaptive system that compensates for declining cognitive capacity may mask early symptoms of deterioration that would otherwise prompt clinical evaluation. If the system continuously simplifies its language in response to declining comprehension scores, neither the user nor their caregivers may recognize the progression of impairment. Safeguards for elderly populations should include (a) longitudinal monitoring of cognitive state baselines to detect secular trends that may indicate clinical relevance, (b) caregiver notification protocols (with user consent) when sustained baseline shifts exceed predefined thresholds, and (c) periodic clinical review requirements for long-term deployments in elder care settings.
8.6 Equity and Access
Yuste et al.’s (2017) fourth ethical priority – equality – warns that cognitive enhancement technologies risk exacerbating existing social inequalities. RLbF confronts this concern at multiple levels, and the current framework does not resolve it through architectural design alone.
The digital divide. RLbF training requires participants who own consumer-grade EEG devices, which currently cost several hundred dollars and are marketed primarily to technology enthusiasts in high-income countries. The training population is therefore likely to be biased toward young, educated, affluent individuals from Western, educated, industrialized, rich, and democratic (WEIRD) societies (Henrich et al., 2010). Cognitive response patterns learned from this population may not generalize to users from different socioeconomic, educational, or cultural backgrounds. Even if the trained model is deployed without EEG hardware (via open-loop transfer), its learned communication policy reflects the cognitive preferences and response patterns of the training population. Users from underrepresented backgrounds may receive communication that is optimized for cognitive dynamics they do not share. This is not a hypothetical concern: it is structurally identical to the well-documented problem of training data bias in machine learning systems more broadly, but with the added dimension that the bias operates on neurophysiological response patterns rather than behavioral preferences. Addressing this requires deliberate recruitment of diverse training populations across socioeconomic strata, geographic regions, educational backgrounds, and age groups, as well as evaluation of the trained model’s communication effectiveness across demographic categories not represented in training.
Cultural bias in cognitive state norms. The cognitive state constructs operationalized in the RLbF reward function – workload, enjoyment, focus – are not culturally neutral. What constitutes “manageable workload” varies across cultures with different expectations for cognitive effort in communication. In high-context communication cultures (Hall, 1976), a substantial proportion of meaning is conveyed through implication, shared context, and indirect reference, and the cognitive work of interpretation is valued rather than minimized. A model trained to reduce cognitive load may produce communication that is perceived as overly explicit, condescending, or culturally inappropriate in high-context settings. Similarly, norms for emotional expressiveness, appropriate levels of directness, and tolerance for ambiguity vary across cultures in ways that a reward function calibrated to one cultural context may not accommodate. The user-configurable cognitive state targets proposed in Section 8.5 offer a partial remedy, but they place the burden of cultural accommodation on the individual user rather than incorporating cultural variation into the system’s default behavior. A more robust approach would include culturally differentiated baseline models and explicit disclosure of the cultural assumptions embedded in the default reward parameterization.
8.7 Dual-Use Scenario Analysis
The dual-use risk of RLbF extends beyond the general observation that empathic technology can be repurposed for manipulation. Three specific misuse scenarios warrant analysis because they illustrate distinct mechanisms through which the framework’s capabilities could be weaponized, and because each requires different countermeasures.
Coercive interrogation and deception detection. An RLbF system deployed with wapp > 0 could be configured to optimize for information extraction: the application-layer reward could incentivize the model to produce utterances that maximize the subject’s cognitive load (to induce stress and reduce executive function), that exploit detected moments of low focus (to insert leading questions when the subject’s guard is down), or that calibrate emotional tone to build false rapport. In an interrogation context, the real-time cognitive state feedback provides the interrogator – or the automated system – with a continuous lie-detection-adjacent signal that reveals which questions produce elevated stress responses, which topics trigger cognitive avoidance, and when the subject’s mental defenses are depleted. Even without explicit deception detection, the system’s ability to adaptively adjust conversational pressure based on real-time cognitive state monitoring constitutes a qualitative escalation in interrogation capability. Countermeasures include regulatory prohibition of RLbF deployment in custodial, law enforcement, or military interrogation contexts, and technical restrictions that prevent reward function configurations from optimizing for cognitive state patterns associated with distress or coercion.
Addictive engagement optimization. A commercial deployer could configure Rapp to maximize session duration, return frequency, or emotional dependency – standard engagement metrics in the attention economy. The RLbF architecture makes this unusually effective because the system can detect, in real time, which conversational strategies trigger the strongest positive cognitive responses (enjoyment spikes, flow states) and which create the aversive states (boredom, frustration) that precede session termination. Combined with the speed advantage described in Section 8.2 (adaptation occurs before conscious awareness) this creates a mechanism for producing compulsive engagement patterns that bypass the user’s deliberative assessment of whether continued interaction is in their interest. The structural analogy to variable-ratio reinforcement schedules in gambling (Schull, 2012) is direct: the system can learn to vary its reward delivery (moments of high communicative resonance interspersed with controlled frustration) to maximize behavioral persistence. Countermeasures include prohibiting engagement-metric-based reward components in Rapp, mandating session duration limits with mandatory cooling-off periods, and requiring independent audit of deployed reward functions to verify that no engagement-maximizing objective is operative.
Political influence and opinion manipulation. An RLbF system trained to monitor cognitive responses to politically relevant content could identify which framing strategies, emotional appeals, and information-density levels are most effective at shifting a specific user’s cognitive engagement with political topics. Unlike current targeted political advertising, which infers political susceptibility from behavioral traces (clicks, likes, browsing history), an RLbF system would have access to real-time neurophysiological responses, enabling it to detect cognitive resistance to a message, identify the precise moment when a user’s skepticism diminishes, and adaptively calibrate persuasive messaging to each individual’s cognitive profile. This capability could be deployed at scale for political campaigns, state propaganda, or radicalization. Countermeasures must operate at the regulatory level (extending political advertising transparency requirements to cognitive-state-adaptive AI systems and prohibiting the use of neurophysiological data for political targeting) and at the technical level (restricting access to the cognitive state API for applications that involve political, ideological, or religious content, and implementing domain-specific deployment restrictions in the platform’s access control layer).
These scenarios are not exhaustive, but they illustrate that the dual-use risk of RLbF is not simply that “empathic technology could be misused”: it is that the specific capabilities of real-time cognitive state feedback create qualitatively new attack surfaces that existing regulatory frameworks were not designed to address.
9. Discussion
9.1 Implications for the LLM Post-Training Community
RLbF introduces a fundamentally new class of reward signal for language model post-training, replacing the discrete, voluntary feedback of RLHF (Section 1.2) with involuntary, continuous, real-time measurements of cognitive impact. This distinction has consequences beyond communication style.
The temporal density of the RLbF signal could enable finer-grained credit assignment than any existing post-training method, potentially attributing cognitive state changes to specific sentences or sub-sentence transitions. This temporal resolution could inform better reward modeling even within the standard RLHF paradigm: for instance, by identifying which parts of a response drive positive or negative evaluations.
The involuntary nature of the signal offers a partial deconfounding of “preferred” from “genuinely beneficial.” RLHF-induced sycophancy (Sharma et al., 2024) arises precisely because voluntary feedback rewards matching stated preferences. If RLbF’s brain feedback correlates with genuine communicative benefit, it could produce less sycophantic models – a hypothesis that motivates the diagnostic tests in Section 6.
More broadly, RLbF suggests that the post-training community should consider feedback signals beyond human judgments and AI evaluations. Physiological signals (not just EEG but potentially eye tracking, skin conductance, or other biosignals) represent an underexplored category of reward signals that could complement existing methods. As John Searle put it in “Biological Naturalism”, 2004: “The fact that brain processes cause consciousness does not imply that only brains can be conscious. The brain is a biological machine. Because we do not know exactly how the brain does it we are not yet in a position to know how to do it artificially.”
9.2 Implications for the BCI and Neurotechnology Community
RLbF proposes a novel BCI application (Wolpaw et al., 2002): not communication or control, but reward signal generation for AI training. This inverts the typical BCI paradigm, where neural signals are the output (decoded into commands or communications) rather than the feedback (shaping another system’s behavior). Within Zander and Kothe’s (2011) taxonomy, this places RLbF in the passive BCI category – the user performs no deliberate mental task; their cognitive state is monitored as they naturally engage with generated text.
The closed-loop architecture demonstrates a new modality for BCI interaction. Traditional passive BCIs monitor cognitive state for logging or simple parameter adjustment. RLbF’s closed loop is tighter: cognitive state directly and continuously shapes the content of a generative language model’s output. This creates a form of human-AI interaction where the user’s brain is, in a meaningful sense, co-producing the conversation, not through deliberate commands but through the involuntary cognitive signals that guide the model’s adaptive communication.
For the neurotechnology community, RLbF provides a concrete downstream application that motivates improvements in cognitive state decoding. The framework’s utility is bounded by decoder accuracy: if decoded scores do not reliably reflect cognitive constructs, the reward signal is noise. This creates a clear value proposition for decoder development: better cognitive state decoding is expected to translate to better-trained empathic models. The minimum decoder accuracy requirements for useful RLbF training remain an empirical question, but the framework provides a principled benchmark for evaluating decoder improvements in terms of their downstream effect on language model communication quality.
A second implication is data production. Real-world RLbF deployments could produce conversation-coupled EEG datasets that are rare in today’s literature: utterance histories, response timing, EEG traces, decoder confidences, and downstream outcomes collected in the same interactive loop. In principle, high-confidence decoder outputs could supervise some segments directly, while ambiguous segments might benefit from context-based weak supervision from language models or semi-supervised correction methods. We emphasize that such labels would be pseudo-labels, not ground truth, and would require strict calibration, agreement filters, and held-out validation to avoid circularity.
More broadly, RLbF suggests that the neurotechnology and language model communities may benefit from collaboration at the optimization level (using neurophysiological signals to guide language model behavior) alongside work at the representation level. This optimization agenda is adjacent to, but distinct from, most current EEG foundation model research, and it may be especially actionable in the near term given present limits in transfer and interactive data coverage.
9.3 Current Limitations and Open Challenges
We identify the following limitations of the current work:
Theoretical, not proven yet by empirical results from experiments. The most fundamental limitation is that every empirical claim in this paper is a hypothesis still in need of testing quantitatively in real world conditions. The framework is theoretical and this arXiv version is intended to establish the formalization, the architecture, and the experimental design in a clear manner that will invite in additional researchers to collaborate since these questions are complex and multifaceted for any single group to work on. The goal is for a subsequent journal version to report empirical evidence and conclusions about the theory’s utility, accompanied by a shared repository of RLbF datasets to support replication and extension by the wider research community.
The Signal-Processing Bottleneck: Distributional Shift and Deconvolution. Capturing the distributional shift and deconvolution of users’ cognitive responses remains an open, and complex challenge — presenting a fundamental identifiability problem (cf. Pearl, 2009) and a non-trivial transfer learning problem overlapped regarding within-session domain and distributional shifts. Our proposed linear subtraction model serves merely as a first-order approximation for this problem. It is almost certainly an over-simplification, relying on a 60-second window assumes that the user’s cognitive state within that timeframe averages out to a neutral baseline which we viscerally understand as humans to not be the natural truth.
This assumption breaks down especially during periods of sustained cognitive effort; if a user maintains a state of high workload for a full minute, the moving average will artificially depress the subsequent response estimates. Second, correcting drift via subtraction implies that the shift is purely additive and confined to the latent prediction space. In reality, physiological drift often involves complex transformations—such as spatial rotations or non-linear changes in the raw EEG space—which require advanced transfer learning techniques to adequately correct. Finally, capturing highly ephemeral, short and long latency evoked potentials and event-related potential trains triggered by specific lexical items requires more sophisticated deconvolution models to disentangle the neurological reactions from the broader, second-level averaged cognitive state.
Hardware dependency and population bias. RLbF training requires EEG-equipped participants, limiting the training population to users who own EEG devices and consent to wear them. This population is likely biased toward young, educated, technology-enthusiastic individuals from wealthy countries. In other words, statistically WEIRD people when compared to the entire global population (from Western, Educated, Industrialized, Rich, and Democratic societies). Cognitive response patterns learned during training thus may not generalize to billions of people across all swaths of human society, that remains an empirical question.
Decoder dependency. The framework’s utility depends on the accuracy of the cognitive state decoder. If decoded scores are noisy or biased, the reward signal is correspondingly degraded. What “sufficient accuracy” means for RLbF training convergence is itself an empirical question.
Weak-supervision circularity. If future RLbF systems use context models or LLMs to propose labels for uncertain EEG segments, those pseudo-labels could amplify model biases or create self-confirming training loops. Any such pipeline would need uncertainty calibration, conservative promotion rules, and held-out human-reviewed validation sets before pseudo-labels are treated as training targets.
Resonance-reward operationalizations. The specific target functions for information density matching and emotional tone alignment are starting points, not optimized solutions. They depend on the choice of reference language model and sentiment classifier, creating an operational under-determination that different implementations could resolve differently, producing different trained behaviors.
Voice-mode limitations. The temporal model handles text-based turn-by-turn interaction well but provides only paragraph-level reward attribution for streaming voice delivery, where overlapping utterances create entangled cognitive responses.
Measurement reactivity. Wearing an EEG device during conversation is not ecologically neutral. The awareness of being monitored may alter cognitive responses (a form of Hawthorne effect), and training data collected under monitoring conditions may not generalize perfectly to unmonitored interaction. The open-loop transfer design partially addresses this – the model operates without monitoring at inference – but the training data itself is collected under monitoring.
Ethical irreducibility. The informational power asymmetry between a cognitive-state-aware model and a cognitively opaque user is a permanent structural feature that cannot be fully eliminated by transparency safeguards, especially in real-time. The proposed mitigations reduce harm potential but do not equalize the fundamental imbalance. Similarly, the internally encoded communication-quality goals in Rres (even with wapp = 0) constitute a normative stance about desirable cognitive states that users may not share in all contexts.
10. Conclusion
This paper introduces RLbF as a framework for training language models with decoded neurophysiological feedback. The core idea is to separate EEG decoding from language-model alignment: a decoder estimates cognitive state from EEG, and those estimates are used as a noisy continuous reward for post-training. This framing leaves room for multiple decoder families, including future EEG foundation models, while focusing this paper’s main contribution on the alignment layer – presenting a formal specification of a cognitive state space, the POMDP interaction loop, a temporal delay model, and a three-component reward function with concrete, testable operationalizations grounded in Cognitive Load Theory and therapeutic alliance research.
The three-phase training pipeline is designed to transform a standard instruction-tuned LLM into an empathic agent through progressive stages: learning the vocabulary of cognitive state from synthetic data, grounding it in real human cognitive responses from Isaac session recordings, and optimizing communication policy against the full empathic reward via PPO. The system architecture, realized in the Isaac platform, implements the closed-loop cognitive feedback loop and is designed to evolve from a dual-agent stepping stone to a single post-trained empathic model. We also advance a data-generation hypothesis: if deployed responsibly, closed-loop conversational systems may generate ecologically valid datasets that pair EEG activity with conversation context, model behavior, decoder confidence, and downstream outcomes. Such datasets could later support better cognitive-state predictors and perhaps future EEG foundation models specialized for interactive settings, although this possibility remains prospective and unvalidated in the present work.
This paper’s boldest claim – the hypothesis that communication skills learned from brain feedback persist when EEG hardware is removed, which we call open-loop empathic transfer – determines whether RLbF scales beyond the EEG-equipped training population to serve any user anywhere, or whether its benefits will remain confined to closed-loop deployments in relatively expensive technological environments. Future research efforts should work to elaborate these relationships more clearly. A step in this direction is our design for a controlled experiment with pre-registered analyses to test it, where if the hypothesis holds, RLbF will show to offer a path to language models that communicate not just informatively and helpfully, but with genuine attunement to their listener’s cognitive experience. If it fails, the framework may hold value for instrumented settings but would never converge on the broader ambition of universally empathic communication with systems that are trained to do no harm.
Our mental privacy-preserving ethical framework is not an appendix or a bolt-on feature of this architecture; it is a load-bearing component of the design. The distinction between empathic and persuasive computing, the analysis of informational power asymmetry, the consent requirements for neurological data, and the safeguards against addition and cognitive dependence are as fundamental to the framework’s viability as any mathematical formula. We have attempted to be transparent about what we believe the framework can and cannot guarantee: wapp = 0 precludes externally imposed goals but retains internally encoded communication-quality objectives; transparency is achievable but full informational symmetry is not; safeguards make risks visible but do not eliminate them.
Every empirical claim in this paper is either supported by existing evidence or explicitly labeled as a hypothesis pending validation, and this honesty is deliberate. The RLbF framework proposes a fundamentally new relationship between neural signals and language models: one where the goal is not to teach machines to decode brain signals, but to teach machines to communicate in ways that the brain finds genuinely useful. Validating this framework requires data, experiments, and results that are beyond the scope of this paper, which aims to establish a new formal foundation: a precise, testable, ethically grounded framework for language model improvement that includes not just what users say, but how users think and feel.
Declaration of Interests
All authors work for Arctop Inc. Some systems described rely on proprietary software platforms developed by Arctop (Furman et al., 2021, US Patent Application US20210390366A1), including empathic computing systems and methods for improved human interactions with digital content experiences. The RLbF framework described in this paper builds on cognitive state decoding technology developed by Arctop and proposes the Isaac platform – which integrates Arctop’s real-time EEG decoding – as the implementation architecture (Section 4). This relationship creates a potential conflict of interest in two respects.
First, this paper’s assessment of the feasibility and accuracy of real-time cognitive state decoding (Section 3) relies in part on Arctop’s published technical capabilities, and the author has a financial interest in the commercial success of that technology. Second, the proposed research program, if successful, could increase the value and adoption of Arctop’s decoding platform, creating a direct commercial incentive for the research direction advocated here.
We have attempted to mitigate these conflicts by (a) grounding all empirical claims in published, independently verifiable evidence and clearly labeling all unvalidated claims as hypotheses, (b) designing the RLbF framework to be decoder-agnostic, such that any cognitive state decoder that provides the required score vector could theoretically substitute for Arctop’s system, so the framework’s value does not depend on a specific commercial use or implementation, and (c) presenting an honest ethical analysis (Section 8) that identifies risks and limitations of the proposed approach without minimizing them for commercial advantage. Readers should nonetheless be aware of this relationship when evaluating this paper’s claims about the quality and feasibility of real-time EEG-derived cognitive state decoding in natural environments.
Appendix A: EEG Foundation Model Summaries
This appendix provides per-model summaries for the eight EEG foundation models reviewed in Section 2.4. For the taxonomy, comparative analysis, and key findings, see Sections 2.4.1–2.4.7.
A.1 BENDr (Kostas et al., 2021)
The pioneering EEG foundation model, adapting wav2vec 2.0 from speech recognition. A six-layer CNN encoder with 96× downsampling feeds into an 8-layer transformer with contrastive pretraining on TUEG data from over 10,000 subjects. BENDr established the conceptual framework for EEG foundation models. Its limitations — single pretraining dataset, aggressive downsampling discarding high-frequency information, fixed channel assumptions — define the gaps later models address. By 2025, BENDr has been surpassed on all benchmarks but remains the most independently assessed model (appearing in all three benchmark studies). Notably, EEG-Bench found BENDr outperforms LaBraM on epilepsy detection (0.740 vs. 0.565) despite LaBraM’s general superiority — a task-specific inversion attributed to label imbalance sensitivity.
A.2 BIOT (Yang et al., 2023)
Addresses biosignal heterogeneity through a unified tokenization scheme converting EEG, ECG, and accelerometer data into standardized “biosignal sentences.” Linear attention maintains O(n) complexity. At approximately 3.3M parameters, BIOT is the smallest model; its innovation lies in practical cross-modality tokenization rather than absolute performance. Benchmarks show BIOT benefits dramatically from multi-task learning (63.98% to 71.37% balanced accuracy on the workload task in EEG-FM-Bench), suggesting weak pretrained representations can be effectively regularized.
A.3 LaBraM (Jiang et al., 2024a)
The first EEG foundation model to demonstrate clear scaling behavior, with three sizes (Base 5.8M, Large 46M, Huge 369M) pretrained on approximately 2,500 hours from roughly 20 diverse datasets. Key innovation: a two-stage approach training a VQ-VAE neural tokenizer (8,192 discrete embeddings using Fourier spectrum targets) followed by masked prediction of these codes. LaBraM-Huge achieves the strongest independently verified results on TUAB (0.826 balanced accuracy) and TUEV (0.662 balanced accuracy). Data scaling analysis found performance plateauing after approximately 1,000 hours of pretraining, challenging the assumption that more data always helps. Serves as the de facto standard comparison point.
A.4 EEGPT (Wang et al., 2024)
Addresses the fundamental problem that raw EEG has low signal-to-noise ratio by aligning predictions with high-SNR reference representations rather than reconstructing raw signals. At approximately 10M parameters, achieves performance competitive with LaBraM on several tasks while being far more compact. Notable for claiming strong linear probing results, contradicting the consensus frozen-backbone collapse — a discrepancy likely attributable to differences in evaluation protocol rather than genuinely superior representations.
A.5 CBraMod (Wang, J. et al., 2025)
Introduces the criss-cross transformer, separating spatial attention (across channels) and temporal attention (within channels), reducing computational cost by approximately 32% versus full attention. With only approximately 5M parameters pretrained on 27,062 hours of TUEG data, achieves performance comparable to or exceeding models 5–14× its size across the broadest evaluation of any model: 10 downstream tasks on 12 datasets. EEG-FM-Bench identified CBraMod as the standout performer. The most reproducible and practically accessible model, pretrained on a single publicly available dataset. From the same Zhejiang University group as EEGMamba, creating the only quasi-controlled transformer-vs-SSM comparison in the field.
A.6 EEGMamba (Gui et al., 2025)
The first EEG foundation model based on a state-space architecture (bidirectional Mamba with Spatio-Temporal-Adaptive module and Task-aware Mixture of Experts). Linear O(n) complexity addresses the quadratic scaling bottleneck for long clinical recordings that routinely span hours, far exceeding the approximately 90-second context limit of transformer-based models. Pretrained on 16,724 hours using masked reconstruction. Critical limitation: zero independent benchmark evaluation.
A.7 NeuroLM (Jiang et al., 2024b)
The most radical departure: converting EEG signals into discrete tokens processed by a pretrained GPT-2 backbone. Three-stage pipeline: text-aligned neural tokenizer, autoregressive next-token prediction, multi-task instruction tuning via natural language prompts. Sizes: 254M to 1.7B parameters. The only model enabling multi-task flexibility through natural language instructions, but performance is sobering: NeuroLM-XL underperforms LaBraM-Huge on TUAB (0.797 vs. 0.826) and TUEV (0.468 vs. 0.662) despite 4.6× more parameters and 10× more data. Attributed to the causal attention constraint and the “domain alignment tax” of forcing EEG tokens into text embedding space. Zero independent benchmark evaluation of multimodal capabilities.
A.8 ZUNA (Warner et al., 2026)
The first diffusion-based EEG foundation model, trained on the largest corpus: approximately 2 million channel-hours from 208 datasets. 4D Rotary Positional Encoding encodes physical 3D electrode coordinates plus temporal index, enabling arbitrary electrode configurations. Architecture: 380M-parameter transformer encoder-decoder diffusion autoencoder with up to 90% channel dropout during training. Substantially outperforms spherical-spline interpolation for channel reconstruction, with advantage growing at higher dropout rates. However, evaluated exclusively on reconstruction and superresolution — never on downstream classification. Whether its encoder representations are useful for discriminative tasks remains the most obvious experiment no one has conducted.
References
- Al-Shargie, F., Kiguchi, M., Badruddin, N., Dass, S. C., Hasan, A. F. M., and Tang, T. B. (2016). Mental stress assessment using simultaneous measurement of EEG and fNIRS. Biomedical Optics Express, 7(10), 3882-3898. https://doi.org/10.1364/BOE.7.003882
- Anthropic. (2025). Natural Emergent Misalignment from Reward Hacking in Production RL. Technical report. https://arxiv.org/abs/2511.18397
- Arctop. (2023). Real-time cognitive state decoding from consumer-grade EEG. Technical report and product documentation. https://arctop.com
- Babu, N., Mathew, J., and Vinod, A. P. (2025). Large Language Models for EEG: A Comprehensive Survey and Taxonomy. arXiv:2506.06353. https://arxiv.org/abs/2506.06353
- Bilgin, I. P., St-Laurent, M., Bellec, L. P., and Wehbe, L. (2026). Brain-Informed Language Model Training Enables Scalable and Generalizable Alignment with Human Brain Activity. https://openreview.net/forum?id=07S1CPoQYP
- Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., et al. (2022). Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073. https://arxiv.org/abs/2212.08073
- Bjork, R. A. and Bjork, E. L. (2011). Making things hard on yourself, but in a good way: Creating desirable difficulties to enhance learning. In M. A. Gernsbacher, R. W. Pew, L. M. Hough, and J. R. Pomerantz (Eds.), Psychology and the Real World: Essays Illustrating Fundamental Contributions to Society (pp. 56-64). Worth Publishers. https://bjorklab.psych.ucla.edu/wp-content/uploads/sites/13/2016/04/EBjork_RBjork_2011.pdf
- Baron-Cohen, S. (1995). Mindblindness: An Essay on Autism and Theory of Mind. MIT Press. https://mitpress.mit.edu/9780262522250/mindblindness/
- Barrett-Lennard, G. T. (1962). Dimensions of therapist response as causal factors in therapeutic change. Psychological Monographs, 76(43), 1-36. https://doi.org/10.1037/h0093918
- Bickmore, T. W., Gruber, A., and Picard, R. W. (2005). Establishing the computer-patient working alliance in automated health behavior change interventions. Patient Education and Counseling, 59(1), 21-30. https://doi.org/10.1016/j.pec.2004.09.008
- Calvo, R. A. and D'Mello, S. K. (2010). Affect Detection: An Interdisciplinary Review of Models, Methods, and Their Applications. IEEE Transactions on Affective Computing, 1(1), 18-37. https://doi.org/10.1109/T-AFFC.2010.1
- Caria, A. (2025). Towards Predictive Communication: The Fusion of Large Language Models and Brain-Computer Interface. Sensors, 25(13), 3987. https://doi.org/10.3390/s25133987
- Chandrasekharan, S. and Jacob, J. E. (2025). Bridging neuroscience and AI: a survey on large language models for neurological signal interpretation. Frontiers in Neuroinformatics, 19, 1561401. https://doi.org/10.3389/fninf.2025.1561401
- Cheng, M., Lee, C., Khadpe, P., Yu, S., Han, D., & Jurafsky, D. (2026). Sycophantic AI decreases prosocial intentions and promotes dependence. Science, 391(6792), aec8352.
- Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. (2017). Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30. https://arxiv.org/abs/1706.03741
- Cornejo-Plaza, M. I., Cippitani, R., and Pasquino, T. (2024). Chilean Supreme Court ruling on the protection of brain activity: neurorights, personal data protection, and neurodata. Frontiers in Psychology, 15, 1330439. https://doi.org/10.3389/fpsyg.2024.1330439
- Csikszentmihalyi, M. (1990). Flow: The Psychology of Optimal Experience. Harper & Row. https://www.harpercollins.com/products/flow-mihaly-csikszentmihalyi
- Cui, W., Jeong, W., Bhatt, J., Medina, B., Zhu, J., Li, B., et al. (2024). Neuro-GPT: Towards A Foundation Model for EEG. 2024 IEEE International Symposium on Biomedical Imaging (ISBI). https://arxiv.org/abs/2311.03764
- D'Mello, S. K. and Graesser, A. C. (2012). AutoTutor and Affective AutoTutor: Learning by talking with cognitively and emotionally intelligent computers that talk back. ACM Transactions on Interactive Intelligent Systems, 2(4), 23:1-23:39. https://doi.org/10.1145/2395123.2395128
- Davidson, R. J. (1992). Anterior cerebral asymmetry and the nature of emotion. Brain and Cognition, 20(1), 125-151. https://doi.org/10.1016/0278-2626(92)90065-T
- Davis, M. H. (1983). Measuring individual differences in empathy: Evidence for a multidimensional approach. Journal of Personality and Social Psychology, 44(1), 113-126. https://doi.org/10.1037/0022-3514.44.1.113
- Ding, N. and Simon, J. Z. (2012). Emergence of neural encoding of auditory objects while listening to competing speakers. Proceedings of the National Academy of Sciences, 109(29), 11854-11859. https://doi.org/10.1073/pnas.1205381109
- Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., and Kiela, D. (2024). KTO: Model Alignment as Prospect Theoretic Optimization. International Conference on Machine Learning (ICML 2024). https://proceedings.mlr.press/v235/ethayarajh24a.html
- Eysenck, M. W., Derakshan, N., Santos, R., and Calvo, M. G. (2007). Anxiety and cognitive performance: Attentional control theory. Emotion, 7(2), 336-353. https://doi.org/10.1037/1528-3542.7.2.336
- Fidencio, A. X., Grun, F., Klaes, C., and Iossifidis, I. (2025). Error-related Potential driven Reinforcement Learning for adaptive Brain-Computer Interfaces. arXiv:2502.18594. https://arxiv.org/abs/2502.18594
- Fogg, B. J. (2003). Persuasive Technology: Using Computers to Change What We Think and Do. Morgan Kaufmann. https://doi.org/10.1016/B978-1-55860-643-2.X5000-8
- Fu, J., Zhao, X., Yao, C., Wang, H., Han, Q., and Xiao, Y. (2025). Reward Shaping to Mitigate Reward Hacking in RLHF. arXiv:2502.18770. https://arxiv.org/abs/2502.18770
- Furman, D. and Kwalwasser, E. (2021). Empathic Computing System and Methods for Improved Human Interactions With Digital Content Experiences. US Patent Application US20210390366A1, Arctop LTD. https://patents.google.com/patent/US20210390366A1
- Gallese, V. and Goldman, A. (1998). Mirror neurons and the simulation theory of mind-reading. Trends in Cognitive Sciences, 2(12), 493-501. https://doi.org/10.1016/S1364-6613(98)01262-5
- Gevins, A., Smith, M. E., McEvoy, L., and Yu, D. (1997). High-resolution EEG mapping of cortical activation related to working memory. Cerebral Cortex, 7(4), 374-385. https://doi.org/10.1093/cercor/7.4.374
- Giraud, A.-L. and Poeppel, D. (2012). Cortical oscillations and speech processing: emerging computational principles and operations. Nature Neuroscience, 15(4), 511-517. https://doi.org/10.1038/nn.3063
- Goldman, A. I. (2006). Simulating Minds: The Philosophy, Psychology, and Neuroscience of Mindreading. Oxford University Press. https://doi.org/10.1093/0195138929.001.0001
- Gui, Y., Chen, M., Su, Y., Luo, G., and Yang, Y. (2025). EEGMamba: Bidirectional State Space Model with Mixture of Experts for EEG Multi-task Classification. arXiv:2407.20254. https://arxiv.org/abs/2407.20254
- Guo, S., Zhang, B., Liu, T., Liu, T., Khalman, M., Llinares, F., et al. (2024). Direct Language Model Alignment from Online AI Feedback. arXiv:2402.04792. https://arxiv.org/abs/2402.04792
- Hatcher, R. L. and Gillaspy, J. A. (2006). Development and validation of a revised short version of the Working Alliance Inventory. Psychotherapy Research, 16(1), 12-25. https://doi.org/10.1080/10503300500352500
- Hall, E. T. (1976). Beyond Culture. Anchor Books. https://www.penguinrandomhouse.com/books/53427/beyond-culture-by-edward-t-hall/
- Henrich, J., Heine, S. J., and Norenzayan, A. (2010). The weirdest people in the world? Behavioral and Brain Sciences, 33(2-3), 61-83. https://doi.org/10.1017/S0140525X0999152X
- Horvath, A. O. and Symonds, B. D. (1991). Relation between working alliance and outcome in psychotherapy: A meta-analysis. Journal of Counseling Psychology, 38(2), 139-149. https://doi.org/10.1037/0022-0167.38.2.139
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. International Conference on Learning Representations (ICLR 2022). https://arxiv.org/abs/2106.09685
- Ienca, M. and Andorno, R. (2017). Towards new human rights in the age of neuroscience and neurotechnology. Life Sciences, Society and Policy, 13(1), 5. https://doi.org/10.1186/s40504-017-0050-1
- Jiang, W.-B., Zhao, L., and Lu, B.-L. (2024a). Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. International Conference on Learning Representations (ICLR 2024). https://openreview.net/forum?id=QzTpTRVtrP
- Jiang, W.-B., Wang, Y., Lu, B.-L., and Li, D. (2024b). NeuroLM: A Universal Multi-task Foundation Model for Bridging the Gap between Language and EEG Signals. arXiv:2409.00101. https://arxiv.org/abs/2409.00101
- Kastrati, A., Bürki, J., Lauer, J., Xuan, C., Iaquinto, R., and Wattenhofer, R. (2025). EEG-Bench: A Benchmark for EEG Foundation Models in Clinical Applications. Advances in Neural Information Processing Systems, 38. https://arxiv.org/abs/2512.08959
- Kamzanova, A. T., Kustubayeva, A. M., and Matthews, G. (2014). Use of EEG workload indices for diagnostic monitoring of vigilance decrement. Human Factors, 56(6), 1136-1149. https://doi.org/10.1177/0018720814525628
- Katahira, K., Yamazaki, Y., Yamaoka, C., Ozaki, H., Nakagawa, S., and Nagata, N. (2018). EEG correlates of the flow state. Frontiers in Psychology, 9, 300. https://doi.org/10.3389/fpsyg.2018.00300
- Kirk, R., Mediratta, I., Nalmpantis, C., Luketina, J., Hambro, E., Grefenstette, E., et al. (2024). Understanding the Effects of RLHF on LLM Generalisation and Diversity. International Conference on Learning Representations (ICLR 2024). https://openreview.net/forum?id=PXD3FAVHJT
- Kostas, D., Aroca-Ouellette, S., and Rudzicz, F. (2021). BENDr: Using Transformers and a Contrastive Self-Supervised Learning Task to Learn From Massive Amounts of EEG Data. Frontiers in Human Neuroscience, 15, 653659. https://doi.org/10.3389/fnhum.2021.653659
- Koelstra, S., Muhl, C., Soleymani, M., Lee, J. S., Yazdani, A., Ebrahimi, T., et al. (2012). DEAP: A Database for Emotion Analysis using Physiological Signals. IEEE Transactions on Affective Computing, 3(1), 18-31. https://doi.org/10.1109/T-AFFC.2011.15
- Kraskov, A., Stogbauer, H., and Grassberger, P. (2004). Estimating mutual information. Physical Review E, 69(6), 066138. https://doi.org/10.1103/PhysRevE.69.066138
- Kuruppu, G., Wagh, N., Kremen, V., Pati, S., Worrell, G., and Varatharajah, Y. (2025). EEG Foundation Models: A Critical Review of Current Progress and Future Directions. arXiv:2507.11783. https://arxiv.org/abs/2507.11783
- Lakens, D. (2017). Equivalence Tests: A Practical Primer for t Tests, Correlations, and Meta-Analyses. Social Psychological and Personality Science, 8(4), 355-362. https://doi.org/10.1177/1948550617697177
- Lee, H., Phatale, S., Mansoor, H., Mesnard, T., Ferret, J., Lu, K. R., et al. (2023). RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback. arXiv:2309.00267. https://arxiv.org/abs/2309.00267
- Lopez-Paz, D., Bottou, L., Scholkopf, B., and Vapnik, V. (2016). Unifying distillation and privileged information. International Conference on Learning Representations (ICLR 2016). https://arxiv.org/abs/1511.03643
- Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., et al. (2018). A review of classification algorithms for EEG-based brain-computer interfaces: a 10 year update. Journal of Neural Engineering, 15(3), 031005. https://doi.org/10.1088/1741-2552/aab2f2
- Mesgarani, N. and Chang, E. F. (2012). Selective cortical representation of attended speaker in multi-talker speech perception. Nature, 485(7397), 233-236. https://doi.org/10.1038/nature11020
- Mishra, A., Shukla, S., Torres, J., Gwizdka, J., and Roychowdhury, S. (2024). Thought2Text: Text Generation from EEG Signal using Large Language Models. arXiv:2410.07507. https://arxiv.org/abs/2410.07507
- Muhl, C., Allison, B., Nijholt, A., and Chanel, G. (2014). A survey of affective brain computer interfaces. Brain-Computer Interfaces, 1(2), 66-84. https://doi.org/10.1080/2326263X.2014.912881
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C. L., Mishkin, P., et al. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35. https://arxiv.org/abs/2203.02155
- Pearl, J. (2009). Causality: Models, Reasoning, and Inference. 2nd edition. Cambridge University Press. https://doi.org/10.1017/CBO9780511803161
- Picard, R. W. (1997). Affective Computing. MIT Press. https://mitpress.mit.edu/9780262661157/affective-computing/
- Premack, D. and Woodruff, G. (1978). Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4), 515-526. https://doi.org/10.1017/S0140525X00076512
- Rafailov, R., Sharma, A., Mitchell, E., Manning, C. D., Ermon, S., and Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Advances in Neural Information Processing Systems, 36. https://arxiv.org/abs/2305.18290
- Rashkin, H., Smith, E. M., Li, M., and Boureau, Y.-L. (2019). Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), 5370-5381. https://aclanthology.org/P19-1534/
- Risko, E. F. and Gilbert, S. J. (2016). Cognitive Offloading. Trends in Cognitive Sciences, 20(9), 676-688. https://doi.org/10.1016/j.tics.2016.07.002
- Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., and Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225-237. https://doi.org/10.3758/PBR.16.2.225
- Saby, J. N. and Marshall, P. J. (2012). The Utility of EEG Band Power Analysis in the Study of Infancy and Early Childhood. Developmental Neuropsychology, 37(3), 253-273. https://doi.org/10.1080/87565641.2011.614663
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347. https://arxiv.org/abs/1707.06347
- Schull, N. D. (2012). Addiction by Design: Machine Gambling in Las Vegas. Princeton University Press. https://press.princeton.edu/books/paperback/9780691160887/addiction-by-design
- Sharma, M., Tong, M., Korbak, T., Duvenaud, D., Askell, A., Bowman, S. R., et al. (2024). Towards Understanding Sycophancy in Language Models. International Conference on Learning Representations (ICLR 2024). https://openreview.net/forum?id=tvhaxkMKAn
- Sitaram, R., Ros, T., Stoeckel, L., Haller, S., Scharnowski, F., Lewis-Peacock, J., et al. (2017). Closed-loop brain training: the science of neurofeedback. Nature Reviews Neuroscience, 18(2), 86-100. https://doi.org/10.1038/nrn.2016.164
- Sorino, P., Biancofiore, G. M., Lofu, D., Colafiglio, T., Lombardi, A., Narducci, F., et al. (2024). ARIEL: Brain-Computer Interfaces meet Large Language Models for Emotional Support Conversation. Adjunct Proceedings of the 32nd ACM Conference on User Modeling, Adaptation and Personalization (UMAP Adjunct '24), Cagliari, Italy. https://doi.org/10.1145/3631700.3665193
- Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., et al. (2020). Learning to summarize from human feedback. Advances in Neural Information Processing Systems, 33. https://arxiv.org/abs/2009.01325
- Sweller, J. (1988). Cognitive load during problem solving: Effects on learning. Cognitive Science, 12(2), 257-285. https://doi.org/10.1207/s15516709cog1202_4
- Ullman, T. (2023). Large Language Models Fail on Trivial Alterations to Theory-of-Mind Tasks. arXiv:2302.08399. https://arxiv.org/abs/2302.08399
- UNESCO. (2025). Recommendation on the ethics of neurotechnology. https://www.unesco.org/en/ethics-neurotech/recommendation
- Vapnik, V. and Vashist, A. (2009). A new learning paradigm: Learning using privileged information. Neural Networks, 22(5-6), 544-557. https://doi.org/10.1016/j.neunet.2009.06.042
- Wang, G., Liu, W., He, Y., Xu, C., Ma, L., and Li, H. (2024). EEGPT: Pretrained Transformer for Universal and Reliable Representation of EEG Signals. Advances in Neural Information Processing Systems, 37. https://proceedings.neurips.cc/paper_files/paper/2024/hash/4540d267eeec4e5dbd9dae9448f0b739-Abstract-Conference.html
- Wang, J., Zhao, S., Luo, Z., Zhou, Y., Jiang, H., Li, S., et al. (2025). CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding. International Conference on Learning Representations (ICLR 2025). https://openreview.net/forum?id=NPNUHgHF2w
- Warner, C., Mago, J., Huml, J. R., Osman, M., and Millidge, B. (2026). ZUNA: Flexible EEG Superresolution with Position-Aware Diffusion Autoencoders. arXiv:2602.18478. https://arxiv.org/abs/2602.18478
- Wobrock, D., Frey, J., Graeff, D., de la Riviere, J.-B., Castet, J., and Lotte, F. (2015). Continuous Mental Effort Evaluation during 3D Object Manipulation Tasks based on Brain and Physiological Signals. INTERACT 2015, Lecture Notes in Computer Science, vol. 9297, 472-487. https://doi.org/10.1007/978-3-319-22701-6_35
- Wolpaw, J. R., Birbaumer, N., McFarland, D. J., Pfurtscheller, G., and Vaughan, T. M. (2002). Brain-computer interfaces for communication and control. Clinical Neurophysiology, 113(6), 767-791. https://doi.org/10.1016/S1388-2457(02)00057-3
- Xiong, W., Li, J., Li, J., Zhu, K., and Jiang, C. (2025). EEG-FM-Bench: A Comprehensive Benchmark for the Systematic Evaluation of EEG Foundation Models. arXiv:2508.17742. https://arxiv.org/abs/2508.17742
- Xu, S., Fu, W., Gao, J., Ye, W., Liu, W., Mei, Z., et al. (2024). Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study. International Conference on Machine Learning (ICML 2024). https://proceedings.mlr.press/v235/xu24h.html
- Yang, C., Westover, M. B., and Sun, J. (2023). BIOT: Biosignal Transformer for Cross-data Learning in the Wild. Advances in Neural Information Processing Systems, 36. https://openreview.net/forum?id=c2LZyTyddi
- Yang, L., Sun, Q., Li, A., and Van Hulle, M. M. (2026). Are EEG Foundation Models Worth It? Comparative Evaluation with Traditional Decoders in Diverse BCI Tasks. International Conference on Learning Representations (ICLR 2026). https://openreview.net/forum?id=5Xwm8e6vbh
- Yuste, R., Goering, S., Agüera y Arcas, B., Bi, G., Carmena, J. M., Carter, A., et al. (2017). Four ethical priorities for neurotechnologies and AI. Nature, 551(7679), 159-163. https://doi.org/10.1038/551159a
- Zander, T. O. and Kothe, C. (2011). Towards passive brain-computer interfaces. Journal of Neural Engineering, 8(2), 025005. https://doi.org/10.1088/1741-2560/8/2/025005
- Zhang, J., Shen, J., Tu, W., Zhang, Y., Zhang, H., Gedeon, T., et al. (2026). EEG-Based Brain-LLM Interface for Human Preference Aligned Generation. arXiv:2603.16897. https://arxiv.org/abs/2603.16897
- Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., et al. (2019). Fine-Tuning Language Models from Human Preferences. arXiv:1909.08593. https://arxiv.org/abs/1909.08593